iOS基础
对象本质
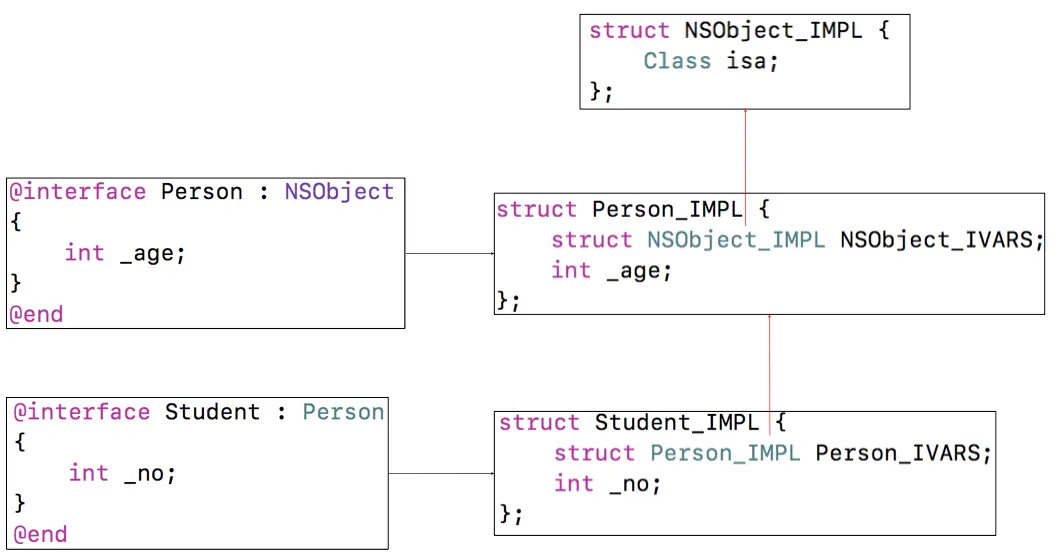
NSObject_IMPL内部:
1
2
3
4
5
struct NSObject_IMPL {
Class isa;
};
// 查看Class本质
typedef struct objc_class *Class;
isa指针在64位架构中占8个字节。也就是说一个NSObjec对象所占用的内存是8个字节
自定义类的内部实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@interface Student : NSObject{
@public
int _no;
int _age;
}
// 通过生成C++文件转换发现Student_IMPL
struct Student_IMPL {
struct NSObject_IMPL NSObject_IVARS;
int _no;
int _age;
};
// 假设 struct NSObject_IMPL NSObject_IVARS 等价于 Class isa;
struct Student_IMPL {
Class *isa;
int _no;
int _age;
};
isa指针8个字节,4个字节的_no ,4个字节的_age
获取对象占用内存的大小,可以通过更便捷的运行时方法来获取
1
2
3
class_getInstanceSize([Student class])
NSLog(@"%zd,%zd", class_getInstanceSize([NSObject class]) ,class_getInstanceSize([Student class]));
// 打印信息 8和16
关于对象内部结构
OC对象主要分为三种:
instance对象: 实例对象1 2
// instance对象就是通过类alloc出来的对象,每次调用alloc都会产生新的instance对象 NSObjcet *object1 = [[NSObjcet alloc] init];
instance对象在内存中存储的信息包括
- isa指针
- 其他成员变量
![instance]()
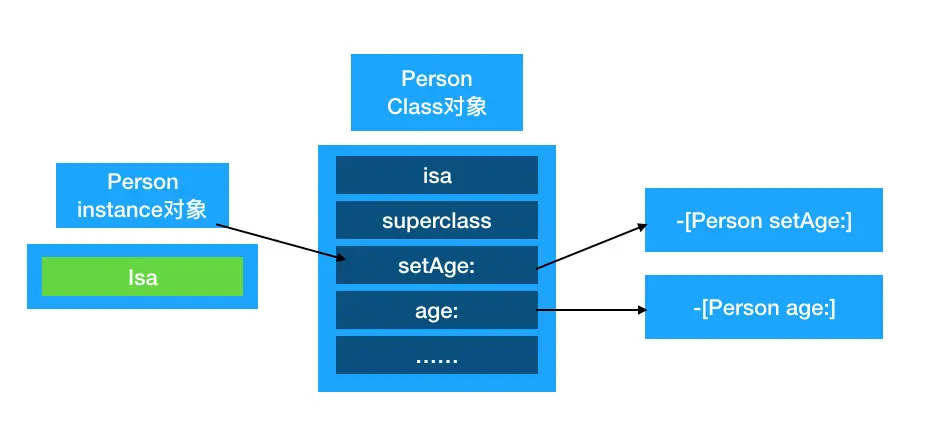
class对象: 类对象1 2 3 4 5 6
// class方法或runtime方法得到一个class对象,class对象也就是类对象 Class objectClass1 = [object1 class]; // runtime Class objectClass4 = object_getClass(object1); // 或 Class objectClass3 = [NSObject class];
每一个类在内存中有且只有一个class对象
class对象在内存中存储的信息主要包括- isa指针
- superclass指针
- 类的属性信息(@property),类的成员变量信息(ivar)
- 类的对象方法信息(instance method),类的协议信息(protocol)
![isa]()
meta-class对象: 元类对象1 2 3 4 5 6
//runtime中传入类对象此时得到的就是元类对象 Class objectMetaClass = object_getClass([NSObject class]); // 而调用类对象的class方法时得到还是类对象,无论调用多少次都是类对象 Class cls = [[NSObject class] class]; Class objectClass3 = [NSObject class]; class_isMetaClass(objectMetaClass) // 判断该对象是否为元类对象
每个类在内存中有且只有一个meta-class对象。
元类对象内存中存储的信息主要包括- isa指针
- superclass指针
- 类的类方法的信息(class method)
![meta-class]()
meta-class对象和class对象的内存结构是一样的,所以meta-class中也有类的属性信息,类的对象方法信息等成员变量



isa 指针:
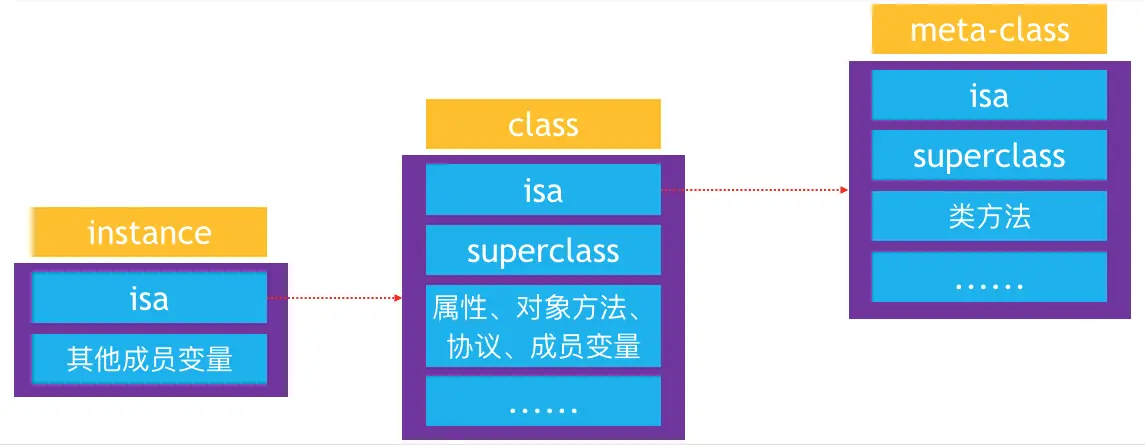
instance的isa指向class- 当调用对象方法时,通过
instance的isa找到class,最后找到对象方法的实现进行调用
- 当调用对象方法时,通过
class的isa指向meta-class- 当调用类方法时,通过
class的isa找到meta-class,最后找到类方法的实现进行调用
- 当调用类方法时,通过
class对象的superclass指针:
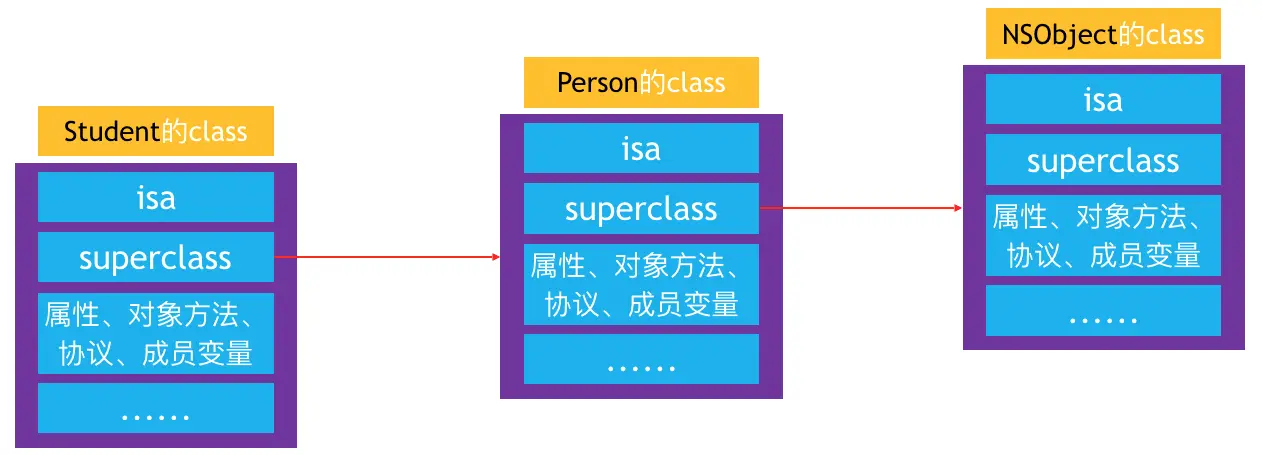
- 当Student的instance对象要调用Person的对象方法时,会先通过isa找到Student的class,然后通过superclass找到Person的class,最后找到对象方法的实现进行调用
- 同样如果Person发现自己没有响应的对象方法,又会通过Person的superclass指针找到NSObject的class对象,去寻找相应的方法
meta-class对象的superclass指针
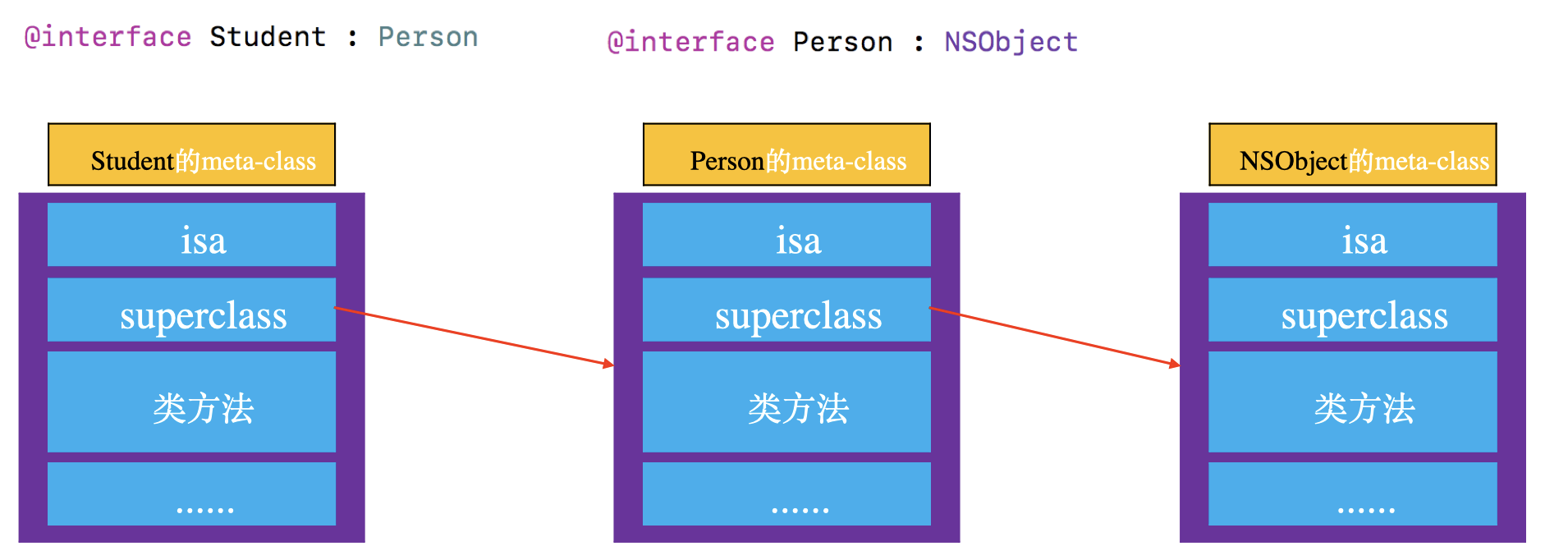
- 当Student的class要调用Person的类方法时,会先通过
isa找到student的meta-class,然后通过superclass找到Person的meta-class,最后找到类方法的实现进行调用。
isa指向图总结:
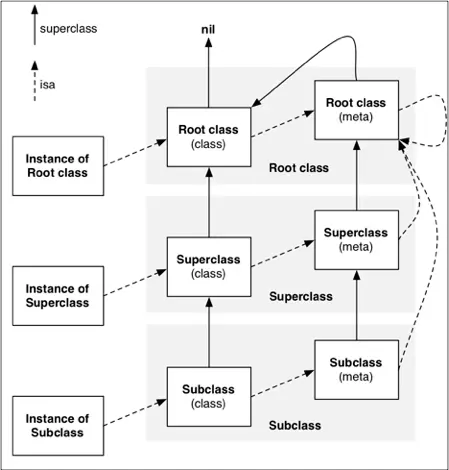
对isa、superclass总结
1
2
3
4
5
6
7
1.instance的isa指向class
2.class的isa指向meta-class
3.meta-class的isa指向基类的meta-class,基类的isa指向自己
4.class的superclass指向父类的class,如果没有父类,superclass指针为nil
meta-class的superclass指向父类的meta-class,基类的meta-class的superclass指向基类的class
5.instance调用对象方法的轨迹,isa找到class,方法不存在,就通过superclass找父类
6.class调用类方法的轨迹,isa找meta-class,方法不存在,就通过superclass找父类
struct objc_class的结构:

面试题
1
2
3
4
5
6
7
8
一个NSObject对象占用多少内存?
答:一个指针变量所占用的大小(64bit占8个字节,32bit占4个字节)
对象的isa指针指向哪里?
答:instance对象的isa指针指向class对象,class对象的isa指针指向meta-class对象,meta-class对象的isa指针指向基类的meta-class对象,基类自己的isa指针也指向自己。
OC的类信息存放在哪里?
答:成员变量的具体值存放在instance对象。对象方法,协议,属性,成员变量信息存放在class对象。类方法信息存放在meta-class对象。
KVO
KVO的全称时Key Value Obsering,俗称键值监听,可以用于监听某个对象属性值的改变。指定的被观察的对象属性被修改后,KVO 就会自动通知相应的观察者。
未使用KVO监听的对象
使用KVO监听的对象:
_NSSet*ValueAndNotify内部实现
1
2
3
[self willChangeValueForKey: @age];
// 原来的Setter方法
[self didChangeValueForKey: @age];
- 调用
willChangeValueForKey方法 - 调用原来
Setter方法实现 - 调用
didChangeValueForKey方法,调用这个方法时内部会调用observer的observeValueForKeyPath:ofObject:change:context:方法。
KVO 底层原理:
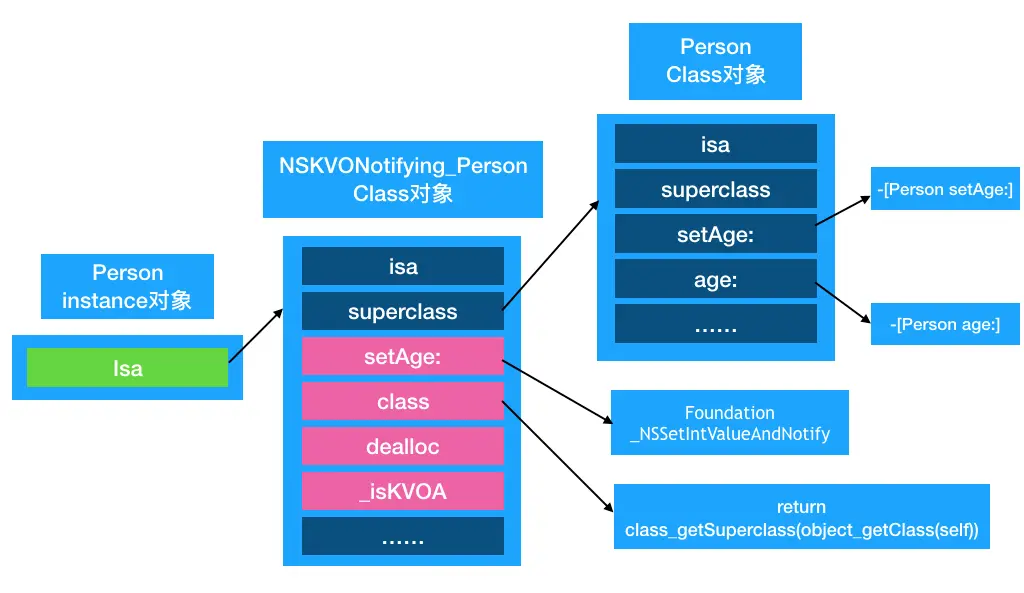
KVO是使用isa-swizzling的技术实现的- 注册KVO观察者后,观察对象的isa指针指向会发生改变,会生成中间类
NSKVONotifying_XXX,动态生成的中间类内部会重写父类的方法。 isa指针指向维护分配表的对象的类,该分派表实质上包含指向该类实现的方法的指针以及其他数据- 对象的属性
注册观察者时,将修改观察对象的isa指针,指向中间类而不是真实类。isa指针的值不一定反映实例的实际类
- 实例对象
isa的指向在注册 KVO 观察者之后,由原有类更改为指向中间类(NSKVONotifying_原有类名)中间类重写了观察属性的setter方法、class、dealloc、_isKVOA方法- dealloc 方法中,移除 KVO 观察者之后,实例对象
isa指向由中间类更改为原有类中间类从创建后,就一直存在内存中,不会被销毁
面试题:
1
2
3
4
5
1.iOS用什么方式实现对一个对象的KVO?(KVO的本质是什么?)
当一个对象使用了KVO监听,iOS系统会修改这个对象的isa指针,改为指向一个全新的通过Runtime动态创建的子类,子类拥有自己的set方法实现,set方法实现内部会顺序调用willChangeValueForKey方法、原来的setter方法实现、didChangeValueForKey方法,而didChangeValueForKey方法内部又会调用监听器的observeValueForKeyPath:ofObject:change:context:监听方法。
2.如何手动触发KVO
答. 被监听的属性的值被修改时,就会自动触发KVO。如果想要手动触发KVO,则需要我们自己调用willChangeValueForKey和didChangeValueForKey方法即可在不改变属性值的情况下手动触发KVO,并且这两个方法缺一不可。
KVC
KVC俗称键值编码(Key-Value Coding,简称KVC)是一种编程技术,它允许你通过key来访问和修改对象的属性。KVC是一种强大的机制,允许你在运行时动态地访问和修改对象的属性。然而,由于其动态特性,可能会导致类型安全问题,应谨慎使用。
KVC的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
class Person {
@objc dynamic var name: String = "John"
var age: Int = 30
}
let person = Person()
// 使用KVC设置属性值
person.setValue("Alice", forKey: "name")
// 使用KVC获取属性值
if let name = person.value(forKey: "name") as? String {
print(name) // 输出 "Alice"
}
setValue: forKey: 原理
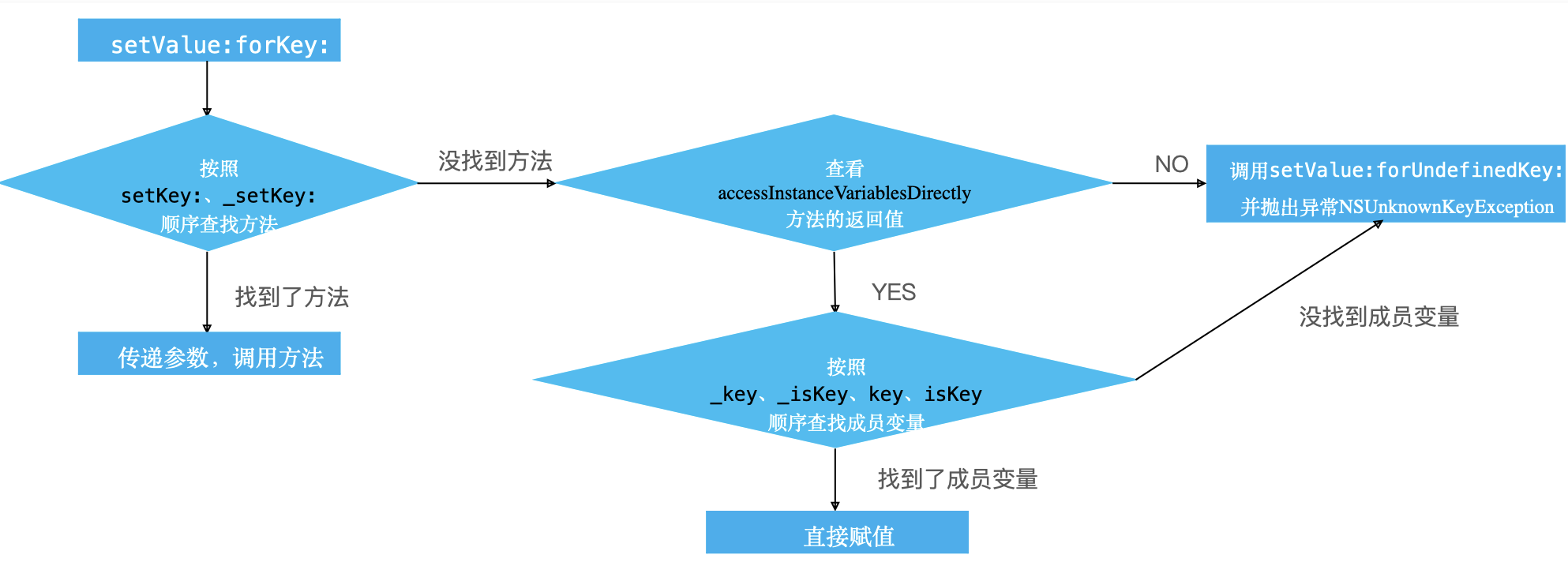
accessInstanceVariablesDirectly 默认返回值时YES
valueForKey: 的原理
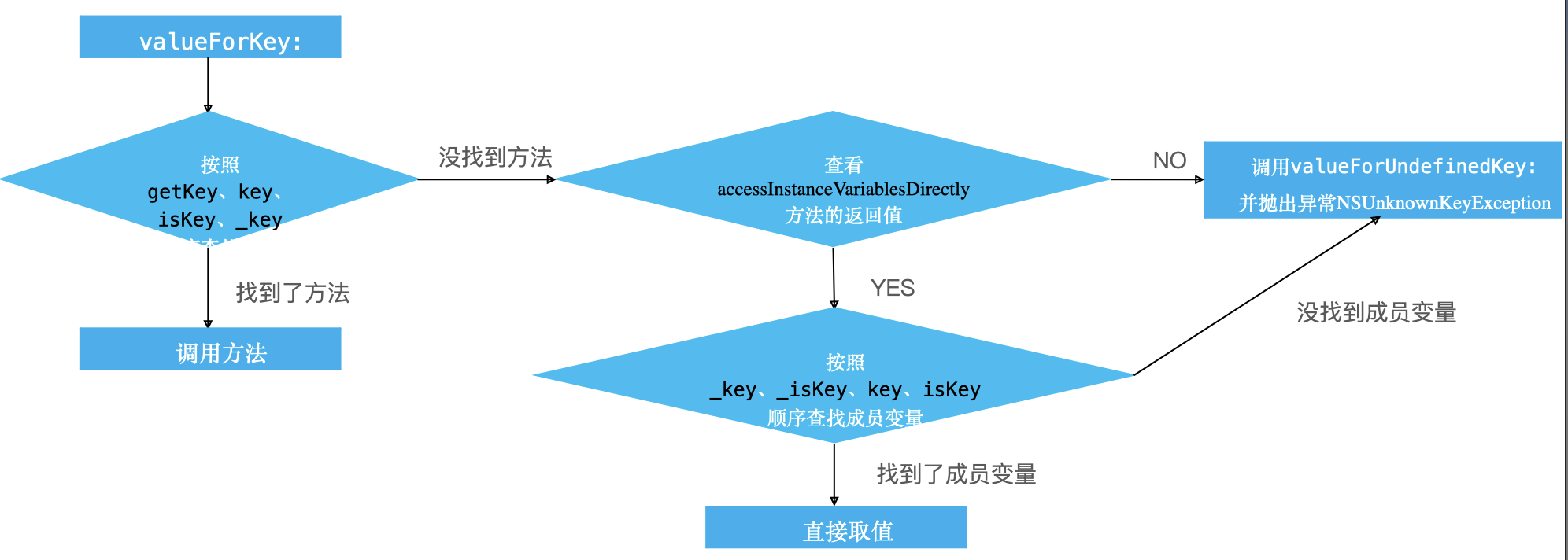
KVC详细流程:

Category & Extension
Category能否添加成员变量?如果可以,如何给Category添加成员变量?
答:不能直接添加成员变量,但是可以通过runtime的方式间接实现添加成员变量的效果。
1
2
3
4
5
6
7
8
9
10
11
12
typedef OBJC_ENUM(uintptr_t, objc_AssociationPolicy) {
OBJC_ASSOCIATION_ASSIGN = 0, // 指定一个弱引用相关联的对象
OBJC_ASSOCIATION_RETAIN_NONATOMIC = 1, // 指定相关对象的强引用,非原子性
OBJC_ASSOCIATION_COPY_NONATOMIC = 3, // 指定相关的对象被复制,非原子性
OBJC_ASSOCIATION_RETAIN = 01401, // 指定相关对象的强引用,原子性
OBJC_ASSOCIATION_COPY = 01403 // 指定相关的对象被复制,原子性
};
// 通过runtime的方式间接实现添加成员变量
objc_getAssociatedObject(self, @"name");
objc_setAssociatedObject(self, @"name",name, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
objc_removeAssociatedObjects(self);
Block
block本质上也是一个oc对象,他内部也有一个isa指针。block是封装了函数调用以及函数调用环境的OC对象。
1
2
3
4
5
6
7
// Block内部结构
struct __block_impl {
void *isa;
int Flags;
int Reserved;
void FuncPtr;
}
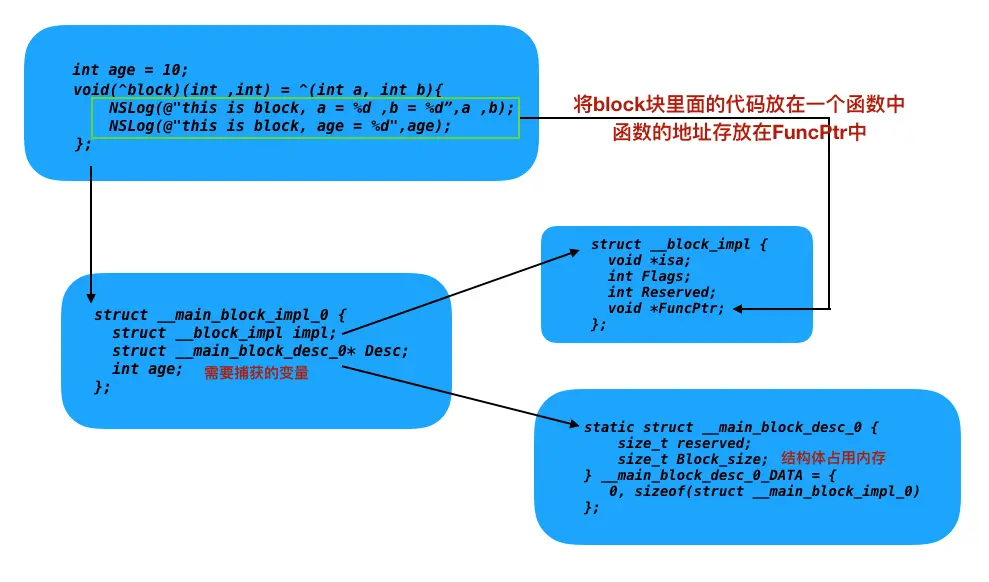
Block变量捕获机制
为了保证block内部能够正常访问外部的变量,block有一个变量捕获机制。
局部变量
auto 变量
auto变量,离开作用域就销毁,局部变量前面自动添加auto关键字。自动变量会捕获到block内部,也就是说block内部会专门新增加一个参数来存储变量的值。auto只存在于局部变量中,访问方式为值传递static 变量
static 修饰的变量为指针传递,同样会被block捕获。
全局变量
block不需要捕获全局变量,因为全局变量无论在哪里都可以访问。

局部变量都会被block捕获,自动变量是值捕获,静态变量为地址捕获。全局变量则不会被block捕获
Block 类型
block 是继承自NSBlock类型,而NSBlock继承于NSObjcet。那么block其中的isa指针其实是来自NSObject中的。 block 有3中类型
1
2
3
__NSGlobalBlock__ ( _NSConcreteGlobalBlock )
__NSStackBlock__ ( _NSConcreteStackBlock )
__NSMallocBlock__ ( _NSConcreteMallocBlock )
block 内存管理
Objective-C中的block(也称为闭包)是一种特殊的数据结构,它允许你将一些代码段(一段代码块)存储在变量中,然后在运行时执行。Block可以捕获和存储对其所创建环境中变量的引用,这就涉及到内存管理的问题。以下是Objective-C中block内存管理的几个关键点:
- 所有权属性:
- 当一个block作为属性或者方法的参数被赋值时,它默认是被
assign操作的,这意味着不会增加对象的引用计数。如果block需要引用对象,并且你希望增加对象的引用计数,可以使用strong或copy属性修饰符。
- 当一个block作为属性或者方法的参数被赋值时,它默认是被
- 自动引用计数(ARC):
- 在ARC环境下,block的内存管理变得更加简单。ARC会跟踪block的引用并自动释放不再使用的block。但是,开发者需要注意循环引用的问题。
- 循环引用:
- 如果block捕获了对其所创建环境中对象的强引用,而该对象又持有block的强引用,就会形成循环引用。这会阻止ARC释放这些资源。解决循环引用的一种方法是在block内部使用弱引用(
__weak)或无主引用(__unsafe_unretained)。
- 如果block捕获了对其所创建环境中对象的强引用,而该对象又持有block的强引用,就会形成循环引用。这会阻止ARC释放这些资源。解决循环引用的一种方法是在block内部使用弱引用(
- 栈和堆:
- 在Objective-C中,block可以在栈上或堆上分配。局部作用域的block(没有捕获变量的block)默认在栈上分配。如果block捕获了变量,或者被赋值给一个对象属性,它将被复制到堆上。
- Block的复制:
- 当block被复制到堆上时,如果它捕获了对象的强引用,ARC会确保这些对象的引用计数增加。如果block在栈上,它不会增加捕获对象的引用计数。
- 内存释放:
- 当block的引用计数降到零,即没有任何强引用指向该block时,ARC会自动释放block占用的内存。
- __block修饰符:
- 如果你想在block内部修改捕获的变量,可以使用
__block修饰符。这会使得变量在block内可变,并且可以正确地处理其生命周期。
- 如果你想在block内部修改捕获的变量,可以使用
- NSCopying协议:
- 当block被赋值给遵循
NSCopying协议的对象时,block需要被复制。如果block捕获了对象,那么在复制过程中需要适当地增加这些对象的引用计数。
- 当block被赋值给遵循
Runtime
Objective-C 是面相运行时的语言( runtime oriented language )。Runtime(运行时)机制是编程语言的核心特性之一,特别是在动态语言中。Runtime系统负责管理程序在运行时的行为,包括但不限于对象的创建、消息的发送、内存管理等。以下是Runtime机制的详细解析,以Objective-C为例,因为它提供了丰富的Runtime功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
1. 动态类型识别
Objective-C在运行时可以查询对象的实际类型,这与静态类型语言不同,后者的类型信息在编译时就已经确定。使用objc_object可以获取对象的类信息。
2. 消息发送
Objective-C使用消息机制来调用方法。当发送消息时,实际调用的是对象的objc_msgSend函数。如果消息无法在接收者中找到实现,Runtime会尝试消息转发。
3. 方法解析
Runtime提供了方法解析机制,如果一个对象无法响应某个选择器(即方法名),可以通过实现- (id)resolveInstanceMethod:(SEL)sel;方法来动态地提供方法实现。
4. 消息转发
如果方法解析失败,Runtime会询问对象是否接受某个选择器的转发。通过实现- (BOOL)respondsToSelector:(SEL)aSelector;,对象可以声明它接受转发。如果对象接受转发,可以选择动态地加载方法实现或抛出异常。
5. 动态方法和属性
Objective-C允许在运行时动态添加或修改方法和属性。使用class_addMethod和class_addIvar可以在类中添加新的方法和成员变量。
6. 交换方法
可以使用method_exchangeImplementations函数交换两个方法的实现,这在编写子类时用于改变父类的行为。
7. 协议检查
Runtime可以在运行时检查对象是否遵循某个协议,通过objc_getProtocol和protocol_conformsToProtocol函数。
8. 类和对象的创建
Objective-C可以在运行时动态创建类和对象,使用objc_getClass和objc_allocateObject函数。
9. 内存管理
Objective-C的Runtime系统负责管理对象的内存,包括引用计数的增减和自动释放池的管理。
10. 属性特性
Objective-C的属性(@property)背后是由setter和getter方法支持的,这些方法在编译时生成。Runtime提供了objc_getAssociatedObject和objc_setAssociatedObject函数来处理属性的关联。
11. 反射
Objective-C提供了一定程度的反射能力,可以在运行时查询类的信息、方法列表、属性列表等。
12. 动态库和插件
Objective-C的Runtime支持动态加载和卸载库,这允许程序在运行时加载新的代码或扩展。
Runtime 消息转发机制
1
2
3
[obj makeText];
// obj是一个对象,makeText是一个函数名称。对于这样一个简单的调用。在编译时RunTime会将上述代码转化成
objc_msgSend(obj,@selector(makeText));
Runtime消息转发机制是其动态特性的核心部分,允许对象在接收到无法识别的消息(即没有实现的方法)时,有机会处理这个消息。以下是消息转发机制的详细解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 消息发送
在Objective-C中,方法调用实际上是消息发送的过程。当你调用一个对象的方法时,实际上是在向这个对象发送一个选择器(Selector),Runtime系统会尝试找到并执行相应的方法实现。
// 方法查找
Runtime首先在接收者的对象中查找对应的方法实现。如果找到了,就直接执行这个方法。
// 方法未实现
如果接收者没有实现这个方法,Runtime会尝试以下步骤:
1.方法解析(Method Resolution)
Runtime调用对象的resolveInstanceMethod:方法,询问对象是否能够提供一个实现。如果对象提供了实现,Runtime将缓存这个实现,并执行它。
2.消息转发(Message Forwarding)
如果方法解析失败,Runtime会询问对象是否愿意转发这个消息。对象可以通过实现forwardingTargetForSelector:方法来指定另一个对象作为消息的接收者。
3.转发消息
如果对象决定转发消息,Runtime将使用新的接收者再次尝试消息发送。如果转发后仍然没有实现,Runtime将进入下一步。
4.无法转发的消息
如果对象没有实现forwardingTargetForSelector:或者转发后的消息仍然无法识别,Runtime将调用doesNotRecognizeSelector:方法。这是一个最后的机会,表明对象无法处理这个消息。
// 抛出异常
如果以上所有步骤都失败了,Runtime将抛出一个异常,通常是NSInvalidArgumentException,表明对象无法响应选择器。
// 动态方法解析
在某些情况下,你可以在运行时动态地为类添加方法实现。这可以通过使用class_addMethod函数来完成。如果添加成功,Runtime将能够识别这个消息,并执行新的方法实现。
注意事项:
- 消息转发机制是Objective-C动态性的重要组成部分,但它也可能导致性能开销,因此应该谨慎使用。
- 消息转发提供了强大的灵活性,但也可能使代码难以理解和调试。在使用时应确保有充分的理由和清晰的文档说明。
- 在实现消息转发或方法解析时,应该注意不要创建无限循环,确保消息最终能够被处理或导致异常。
Objective-C Runtime 是什么?
Objective-C 的 Runtime 是一个运行时库(Runtime Library),它是一个主要使用 C 和汇编写的库,为 C 添加了面相对象的能力并创造了 Objective-C。这就是说它在类信息(Class information) 中被加载,完成所有的方法分发,方法转发,等等。Objective-C runtime 创建了所有需要的结构体,让 Objective-C 的面相对象编程变为可能。
Method Swizzling 原理
在Objective-C中调用一个方法,其实是向一个对象发送消息,查找消息的唯一依据是selector的名字。利用Objective-C的动态特性,可以实现在运行时偷换selector对应的方法实现,达到给方法挂钩的目的。每个类都有一个方法列表,存放着selector的名字和方法实现的映射关系。IMP有点类似函数指针,指向具体的Method实现。
通过使用 Runtime,开发者可以实现一些高级的功能,比如实现 AOP(面向切面编程)、实现 KVO(键值观察)等。Runtime 提供了一种强大而灵活的方式来扩展和定制 iOS 应用程序的行为。
Runloop
RunLoop 实际上就是一个对象,这个对象管理了其需要处理的事件和消息,并提供了一个入口函数来执行上面 Event Loop 的逻辑。线程执行了这个函数后,就会一直处于这个函数内部 “接受消息->等待->处理” 的循环中,直到这个循环结束(比如传入 quit 的消息),函数返回。在iOS中苹果是如何利用 RunLoop 实现自动释放池、延迟回调、触摸事件、屏幕刷新等功能的。
OSX/iOS 系统中,提供了两个这样的对象:NSRunLoop 和 CFRunLoopRef。 CFRunLoopRef 是在 CoreFoundation 框架内的,它提供了纯 C 函数的 API,所有这些 API 都是线程安全的。 NSRunLoop 是基于 CFRunLoopRef 的封装,提供了面向对象的 API,但是这些 API 不是线程安全的。
在 CoreFoundation 里面关于 RunLoop 有5个类:
1
2
3
4
5
CFRunLoopRef
CFRunLoopModeRef
CFRunLoopSourceRef
CFRunLoopTimerRef
CFRunLoopObserverRef
CFRunLoopSourceRef 是事件产生的地方。Source有两个版本:Source0 和 Source1:
- Source0 只包含了一个回调(函数指针),它并不能主动触发事件。使用时,你需要先调用 CFRunLoopSourceSignal(source),将这个 Source 标记为待处理,然后手动调用 CFRunLoopWakeUp(runloop) 来唤醒 RunLoop,让其处理这个事件。
- Source1 包含了一个 mach_port 和一个回调(函数指针),被用于通过内核和其他线程相互发送消息。这种 Source 能主动唤醒 RunLoop 的线程,其原理在下面会讲到。
CFRunLoopTimerRef 是基于时间的触发器,它和 NSTimer 是toll-free bridged 的,可以混用。其包含一个时间长度和一个回调(函数指针)。当其加入到 RunLoop 时,RunLoop会注册对应的时间点,当时间点到时,RunLoop会被唤醒以执行那个回调。
CFRunLoopObserverRef 是观察者,每个 Observer 都包含了一个回调(函数指针),当 RunLoop 的状态发生变化时,观察者就能通过回调接受到这个变化。可以观测的时间点有以下几个:
1
2
3
4
5
6
7
8
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry = (1UL << 0), // 即将进入Loop
kCFRunLoopBeforeTimers = (1UL << 1), // 即将处理 Timer
kCFRunLoopBeforeSources = (1UL << 2), // 即将处理 Source
kCFRunLoopBeforeWaiting = (1UL << 5), // 即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6), // 刚从休眠中唤醒
kCFRunLoopExit = (1UL << 7), // 即将退出Loop
};
1.RunLoop 的内部逻辑: 接受消息->等待->处理
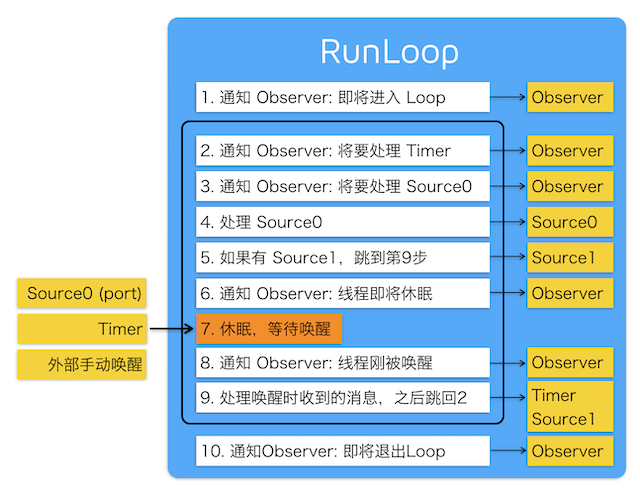
可以看到,实际上 RunLoop 就是这样一个函数,其内部是一个 do-while 循环。当你调用 CFRunLoopRun() 时,线程就会一直停留在这个循环里;直到超时或被手动停止,该函数才会返回。
当iPhone接受到一个触摸事件时,处理过程如下:
1
2
3
4
5
6
7
8
1.通过动作产生触摸事件唤醒处于睡眠状态中的app;
2.使用IOKit.framework将事件封装为 IOHIDEvent 对象;
3.系统通过 mach port 将 IOHIDEvent 对象转发给 SpringBoard.app 处理。SpringBorad 是iPhone手机的桌面管理程序,4.SpringBoard 可以找到能够处理该事件的app,然后将 IOHIDEvent 对象通过mach port转发给对应的App;
5.App的主线程 Runloop 接收到 SpringBoard 转发的消息,触发对应 mach port 的source1回调 __IOHIDeventSystemClientQueueCallback();
6.source1回调内部触发source0回调,__UIApplicationHandleEventQueue();
7.source0内部将IOHIDEvent对象包装为UIEvent对象;
8.source0内部回调 UIApplication 的sendEvnet:方法,将 UIEvent 传递给 UIWindow;
9.UIWindow 接收到 UIEvent 后,就开始寻找合适的 UIResponsder 处理。
2.苹果用 RunLoop 实现的功能
1
2
3
4
5
1. kCFRunLoopDefaultMode: App的默认 Mode,通常主线程是在这个 Mode 下运行的。
2. UITrackingRunLoopMode: 界面跟踪 Mode,用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他 Mode 影响。
3. UIInitializationRunLoopMode: 在刚启动 App 时第进入的第一个 Mode,启动完成后就不再使用。
4: GSEventReceiveRunLoopMode: 接受系统事件的内部 Mode,通常用不到。
5: kCFRunLoopCommonModes: 这是一个占位的 Mode,没有实际作用。
应用场景举例:主线程的 RunLoop 里有两个预置的 Mode:kCFRunLoopDefaultMode 和 UITrackingRunLoopMode。这两个 Mode 都已经被标记为”Common”属性。DefaultMode 是 App 平时所处的状态,TrackingRunLoopMode 是追踪 ScrollView 滑动时的状态。当你创建一个 Timer 并加到 DefaultMode 时,Timer 会得到重复回调,但此时滑动一个TableView时,RunLoop 会将 mode 切换为 TrackingRunLoopMode,这时 Timer 就不会被回调,并且也不会影响到滑动操作。
- AutoreleasePool
- 事件响应
- 手势识别
- 界面更新
- 定时器
- PerformSelecter
- 关于GCD
- 关于网络请求
3.RunLoop 的实际应用举例
AFNetworking
AFURLConnectionOperation 这个类是基于 NSURLConnection 构建的,其希望能在后台线程接收 Delegate 回调。为此 AFNetworking 单独创建了一个线程,并在这个线程中启动了一个 RunLoop。
当需要这个后台线程执行任务时,AFNetworking 通过调用 [NSObject performSelector:onThread:..] 将这个任务扔到了后台线程的 RunLoop 中。
AsyncDisplayKit
UI 线程中一旦出现繁重的任务就会导致界面卡顿,这类任务通常分为3类:排版,绘制,UI对象操作。ASDK 创建了一个名为 ASDisplayNode 的对象,并在内部封装了 UIView/CALayer,它具有和 UIView/CALayer 相似的属性,所有这些属性都可以在后台线程更改,开发者可以只通过 Node 来操作其内部的 UIView/CALayer,这样就可以将排版和绘制放入了后台线程。
多线程
OS有四种多线程编程的技术,分别是:NSThread、pthread、Cocoa NSOperation、GCD(全称:Grand Central Dispatch)。
- NSThread 是 Apple 的 Foundation 框架中的一个类,它提供了多线程编程的功能。NSThread 比其他两个轻量级。缺点:需要自己管理线程的生命周期,线程同步。线程同步对数据的加锁会有一定的系统开销。
- pthread 是一套通用的多线程API,适用于Linux\Windows\Unix,跨平台,可移植,使用C语言,生命周期需要程序员管理,IOS开发中使用很少。
- Cocoa NSOperation 它不需要关心线程管理, 数据同步的事情,可以把精力放在自己需要执行的操作上。Cocoa operation相关的类是NSOperation, NSOperationQueue.NSOperation是个抽象类, 使用它必须用它的子类,可以实现它或者使用它定义好的两个子类: NSInvocationOperation和NSBlockOperation.创建NSOperation子类的对象,把对象添加到NSOperationQueue队列里执行。
- GCD Grand Central dispatch(GCD)是Apple开发的一个多核编程的解决方案。在iOS4.0开始之后才能使用。GCD是一个替代NSThread, NSOperationQueue,NSInvocationOperation等技术的很高效强大的技术。
什么是线程安全
线程安全是指在多线程环境中,一个对象或代码块能够在多个线程同时访问时,仍然能够保持其内部状态的正确性。换句话说,线程安全确保了当多个线程尝试同时访问和修改共享数据时,这些操作不会相互干扰,导致数据损坏或不一致。
实现线程安全通常需要以下措施:
1
2
3
4
5
6
7
8
9
10
11
12
互斥锁(Mutex):使用互斥锁可以确保一次只有一个线程能够访问特定的代码段或数据。
同步代码块:在某些编程语言中,可以使用同步代码块来确保一次只有一个线程可以执行代码块内的代码。
原子操作:原子操作是指在执行过程中不会被其他线程中断的操作。许多编程语言提供了原子类型或原子操作的API。
条件变量:条件变量允许线程在某些条件不满足时挂起,直到其他线程修改了共享数据并通知它们。
信号量:信号量是一种计数器,用于控制对共享资源的访问数量。
读写锁:读写锁允许多个读操作同时进行,但写操作会独占访问权。
不可变对象:不可变对象一旦创建,其状态就不能改变,因此它们天然是线程安全的。
线程局部存储:每个线程都有自己的数据副本,避免了共享数据。
避免共享状态:设计系统时,尽量避免共享状态,或者将共享状态限制在最小范围内。
使用线程安全的数据结构:许多编程语言和库提供了线程安全的数据结构,可以直接使用。
在 Swift 中,线程安全可以通过多种方式实现,例如使用 DispatchQueue 来同步线程,或者使用 NSLock、NSRecursiveLock、NSCondition 等 NSOperationQueue 提供的同步原语。Swift 5.5 引入了 actor 模型,提供了一种更现代的方式来处理并发和线程安全问题。
GCD
GCD(Grand Central Dispatch)是苹果公司为iOS、macOS、watchOS和tvOS操作系统提供的一个多核编程技术框架。它允许开发者更高效地利用多核处理器,通过将任务分配到不同的处理器核心上执行,从而提高应用程序的性能和响应速度。
GCD的优势:
- GCD是苹果公司为多核的并行运算提出的解决方案
- GCD会自动利用更多的CPU内核(比如双核、四核)
- GCD会自动管理线程的生命周期(创建线程、调度任务、销毁线程)
- 程序员只需要告诉GCD想要执行什么任务,不需要编写任何线程管理代码
同步和异步的区别:
- 同步:只能在当前线程中执行任务,不具备开启新线程的能力
- 异步:可以在新的线程中执行任务,具备开启新线程的能力(异步主队列不具备)
队列
- 并发队列
- 可以让多个任务并发(同时)执行(自动开启多个线程同时执行任务)
- 并发功能只有在异步(dispatch_async)函数下才有效
- 串行队列
- 让任务一个接着一个地执行(一个任务执行完毕后,再执行下一个任务)
同步 + 主队列(死锁)
- 注意 : 如果dispatch_sync方法是在主线程中调用的,并且传入的队列是主队列,那么会导致死锁
GCD的核心概念包括:
- 队列(Queues):
- GCD使用队列来管理任务(也称为块或闭包)。开发者可以将任务提交到队列中,GCD会自动在可用的处理器核心上执行这些任务。
- 串行队列(Serial Queues):
- 任务按照它们被提交的顺序依次执行。串行队列确保了任务的执行顺序。
- 并行队列(Concurrent Queues):
- 任务可以同时在多个处理器核心上执行。并行队列提高了任务执行的并行性,从而加快了整体的执行速度。
- 主队列(Main Queue):
- 主队列是串行队列,用于处理与用户界面相关的任务。所有更新UI的操作都应该在主队列上执行,以保持界面的响应性。
- 全局队列(Global Queues):
- 全局队列是并行队列,用于执行后台任务。它们有不同的优先级,如低优先级、默认优先级、高优先级等。
GCD(Grand Central Dispatch)的具体使用方法涉及到将任务提交到不同的队列中执行。以下是一些基本的步骤和代码示例,帮助你了解如何在实际编程中使用GCD。
1. 串行队列(Serial Dispatch Queue)
1
2
3
4
5
6
7
let queue = DispatchQueue(label: "com.example.mySerialQueue")
// 将任务提交到串行队列
queue.async {
// 这里执行任务
print("执行任务 - 串行队列")
}
2. 并发队列(Concurrent Dispatch Queue)
1
2
3
4
5
6
7
let concurrentQueue = DispatchQueue(label: "com.example.myConcurrentQueue", attributes: .concurrent)
// 将任务提交到并发队列
concurrentQueue.async {
// 这里执行任务
print("执行任务 - 并发队列")
}
3. 主队列(Main Dispatch Queue)
更新UI时,需要在主队列上执行:
1
2
3
4
DispatchQueue.main.async {
// 更新UI的操作
print("更新UI - 主队列")
}
4. 全局队列(Global Dispatch Queue)
1
2
3
4
5
// 使用全局队列执行任务,可以指定优先级
DispatchQueue.global(qos: .userInitiated).async {
// 这里执行后台任务
print("执行后台任务 - 全局队列")
}
5. 任务组(Dispatch Group)
使用任务组可以等待多个异步任务完成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
let group = DispatchGroup()
// 将任务提交到任务组
group.enter()
DispatchQueue.global().async {
// 执行耗时任务
sleep(2)
print("任务1完成")
group.leave()
}
group.enter()
DispatchQueue.global().async {
// 执行另一个耗时任务
sleep(2)
print("任务2完成")
group.leave()
}
// 等待所有任务完成
group.notify(queue: DispatchQueue.main) {
print("所有任务完成")
}
6. 信号量(Dispatch Semaphore)
使用信号量控制同时执行的任务数量:
1
2
3
4
5
6
7
8
9
10
11
let semaphore = DispatchSemaphore(value: 2)
// 等待信号量
semaphore.wait()
DispatchQueue.global().async {
// 执行任务
print("执行任务 - 信号量控制")
// 信号量的值增加,允许其他等待的线程继续执行
semaphore.signal()
}
注意事项:
- 当你使用GCD时,确保不要在异步队列上执行耗时的任务,除非你确实需要在那个队列上执行。
- 所有的UI更新操作应该在主队列上执行,以避免更新冲突和潜在的线程安全问题。
- 使用任务组和信号量时,要注意正确地管理队列的进入(enter)和离开(leave)以及信号量的等待(wait)和信号(signal)。
- 避免在异步任务中忘记使用
async关键字,这会导致任务在当前线程同步执行,而不是在GCD队列中异步执行。
内存管理
iOS 内存管理是指对于应用程序中的对象内存进行合理分配和释放的过程。在 iOS 中,内存管理主要依靠引用计数(Reference Counting)来实现。以下是 iOS 内存管理的一些核心概念和方法:
- 引用计数:每个对象都有一个引用计数,表示有多少个指针指向该对象。当引用计数为0时,对象会被系统回收。
- retain、release 和 autorelease:开发者可以通过 retain 方法增加对象的引用计数,通过 release 方法减少对象的引用计数,以及通过 autorelease 方法将对象延迟释放。
- 循环引用:如果两个对象互相持有对方的引用,可能导致循环引用,从而导致对象无法被释放。为了避免循环引用,可以使用弱引用(weak reference)或者采用其他方式打破循环引用。
- 自动释放池:通过创建自动释放池,可以让一些临时对象在池中被释放,而不需要手动管理其引用计数。
- ARC(Automatic Reference Counting):ARC 是一种编译器特性,它可以自动插入 retain、release 和 autorelease 方法调用,从而减轻了开发者手动管理引用计数的负担。
- 内存泄漏:内存泄漏是指应用程序中存在大量无法释放的对象,这可能会导致应用程序占用过多内存而变得缓慢或崩溃。开发者需要注意正确地管理对象的引用计数,避免内存泄漏问题。
总体上,iOS 的内存管理需要开发者理解引用计数的工作原理,并正确地管理对象的引用关系,以确保内存得到合理地分配和释放。同时,随着 ARC 技术的成熟,开发者也可以选择使用 ARC 来简化内存管理的工作。
iOS内存管理是确保应用程序高效运行的关键部分。在iOS开发中,内存管理主要涉及以下几个方面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
1. 自动引用计数(ARC, Automatic Reference Counting)
ARC是iOS开发中用于管理内存的主要机制。它自动跟踪对象的引用计数,并在没有强引用时释放对象。
开发者不需要手动调用retain、release或autorelease方法来管理内存。
2. 强引用(Strong References)
在ARC环境下,默认的引用类型是强引用。每个强引用都会增加对象的引用计数。
3. 弱引用(Weak References)
使用weak关键字声明的引用不会增加对象的引用计数。当对象被释放时,弱引用会自动置为nil,避免野指针问题。
4. 无主引用(Unowned References)
使用unowned关键字声明的引用假定其所引用的对象的生命周期至少与其一样长。如果对象先于引用被释放,将导致运行时崩溃。
5. 循环引用
当两个对象互相强引用时,形成循环引用,这会导致内存泄漏。需要使用弱引用或无主引用来打破循环。
6. 内存警告(Memory Warnings)
当系统内存不足时,iOS会发送内存警告。应用程序需要适当响应内存警告,释放不必要的资源。
7. 手动内存管理
在某些情况下,开发者可能需要手动管理内存,例如使用Core Foundation框架的对象或处理非ARC的代码。
8. 内存泄漏
内存泄漏发生在对象不再被使用但无法被释放时。使用Instruments工具可以检测内存泄漏。
9. 内存优化
开发者应优化内存使用,例如通过延迟加载、图片压缩、使用更小的数据结构等方法。
10. 内存屏障(Memory Barriers)
在多线程环境中,内存屏障确保对共享资源的访问顺序正确,避免由于编译器优化导致的不一致问题。
11. 内存缓存
使用NSCache等缓存机制可以存储不常用的对象,当内存不足时,缓存的对象可以被自动清除。
12. 内存监控
Xcode提供了内存监控工具,如Allocations、Leaks和VM Tracker,帮助开发者分析和优化内存使用。
注意点:
- 理解ARC的工作原理,避免不必要的内存管理操作。
- 谨慎使用
@autoreleasepool,因为它只在Objective-C中使用,Swift中不再需要。- 避免过度优化,过早优化可能导致代码复杂和难以维护。
架构
iOS开发中常见的架构模式有:
MVC (Model-View-Controller):
iOS开发中常用的MVC架构是一种设计模式,它将应用程序分为三个主要组件:模型(Model)、视图(View)和控制器(Controller)。这种分离的架构有助于保持代码的组织性和可维护性。以下是对这三个组件的详细解析:
- Model
- 它主要负责数据和业务逻辑,不依赖于用户界面(UI),可以独立于视图进行测试和开发
- View
- 它是应用程序的显示层,负责展示数据(UI界面)给用户,负责展示数据(UI界面)
- 它不包含业务逻辑,只负责展示由模型提供的数据
- Controller
- 充当模型和视图之间的中介或协调者,处理用户输入和更新界面
- 也负责在模型数据更新时更新视图,以反映最新的数据状态
优缺点:
- 优点
- 分离关注点:将数据管理、业务逻辑和用户界面分离,使得每个部分可以独立开发和测试。
- 可维护性:由于组件之间的低耦合,修改和维护变得更加容易。
- 可扩展性:可以轻松添加新功能或修改现有功能,而不影响其他部分。
- 可重用性:模型和视图可以独立于控制器重用。
- 缺点
- 复杂性:随着应用程序的增长,控制器可能会变得复杂和难以管理。
- 过度依赖:视图和模型之间的通信完全依赖于控制器,这可能导致控制器过于庞大。
- 测试困难:由于组件之间的紧密耦合,单独测试模型或视图可能会变得困难。
- Model
MVP (Model-View-Presenter):
MVP是一种软件设计模式,用于分离用户界面(UI)和业务逻辑。这种模式特别适用于需要清晰分离UI和业务逻辑的场景,以便于测试和维护。在iOS开发中,MVP模式可以帮助开发者创建更加模块化和可维护的应用程序。下面是MVP架构的详细解析:- Model
- 与MVC架构中的模型类似,MVP的模型负责管理应用程序的数据和业务逻辑
- View
- 定义界面逻辑,但不持有业务逻辑,只负责显示数据和响应用户交互
- Presenter
- 它充当视图和模型之间的中介,处理业务逻辑,并将数据传递给View
优缺点:
- 优点
- 低耦合:视图与业务逻辑分离,使得代码更加模块化,易于管理和维护。
- 易于测试:由于视图和业务逻辑的分离,可以独立测试模型和呈现器。
- 可重用性:视图和呈现器可以独立于模型重用,提高了代码的复用性。
- 缺点
- 复杂性:引入额外的呈现器层可能会增加项目的复杂性。
- 性能问题:在某些情况下,频繁的视图和呈现器交互可能会影响性能。
- 学习曲线:对于不熟悉MVP的开发者来说,可能需要时间来适应这种架构。
- Model
MVVM (Model-View-ViewModel):
MVVM(Model-View-ViewModel)架构是一种设计模式,它将应用程序分为三个主要组件:模型(Model)、视图(View)和视图模型(ViewModel)。这种模式特别适用于数据驱动的应用程序,如iOS开发中使用SwiftUI或UIKit框架时。以下是对这三个组件的详细解析:
- Model
- 模型负责管理应用程序的数据和业务逻辑
- 不依赖于视图或视图模型,可以独立于UI进行开发和测试
- 通常通过数据绑定或观察者模式与视图模型进行交互
- View
- 视图负责显示用户界面和收集用户输入
- 视图通过数据绑定与视图模型进行交互,视图模型提供数据和用户界面需要的逻辑
- ViewModel
- 视图模型充当视图和模型之间的桥梁,负责处理视图的数据和逻辑。
- 它不直接与UI组件交互,而是通过数据绑定和命令(如RxSwift中的Observables和Actions)与视图进行交互。
优缺点
- 优点
- 低耦合:视图与业务逻辑分离,使得代码更加模块化,易于管理和维护。
- 易于测试:由于视图和业务逻辑的分离,可以独立测试模型和视图模型。
- 可重用性:视图模型可以独立于特定的视图重用,提高了代码的复用性。
- 响应式编程:MVVM通常与响应式编程框架结合使用,如RxSwift,使得状态管理和事件处理更加简洁。
- 缺点
- 学习曲线:对于不熟悉MVVM或响应式编程的开发者来说,可能需要时间来适应这种架构。
- 复杂性:引入视图模型层可能会增加项目的复杂性,尤其是在处理复杂的用户界面时。
- 性能问题:在某些情况下,过度的数据绑定和响应式编程可能会导致性能问题。
1 2 3 4 5 6 7 8 9 10 11 12
MVVM(Model-View-ViewModel)是一种软件架构模式,主要用于分离用户界面(UI)和业务逻辑。这种模式在开发图形用户界面应用程序时非常流行,尤其是在需要处理复杂用户界面和大量数据交互的应用中。以下是一些出现MVVM架构模式的原因: 分离关注点:MVVM通过将视图(View)、模型(Model)和视图模型(ViewModel)分离,使得开发者可以专注于各自独立的部分,提高代码的可维护性和可测试性。 提高代码复用性:由于视图和业务逻辑分离,视图模型可以独立于特定的UI框架,使得业务逻辑更容易被复用。 简化UI开发:视图(View)只负责显示数据,不包含业务逻辑,这使得UI开发更加简单和直观。 数据绑定:MVVM支持数据绑定,这意味着当模型(Model)中的数据发生变化时,视图(View)会自动更新,反之亦然。这减少了手动更新UI的需要,提高了开发效率。 提高测试性:由于业务逻辑被封装在视图模型(ViewModel)中,可以更容易地编写单元测试来验证逻辑的正确性。 支持MVC的改进:MVVM是对MVC(Model-View-Controller)模式的一种改进,它解决了MVC中控制器(Controller)过于臃肿的问题,通过将更多的逻辑转移到视图模型中。 支持异步编程:在现代应用程序开发中,异步编程变得越来越重要。MVVM模式通过将业务逻辑和UI逻辑分离,使得处理异步操作更加清晰和容易。 更好的用户交互:视图模型可以包含与用户交互相关的逻辑,使得视图可以更加专注于展示,而视图模型则处理用户输入和相应的业务逻辑。 适应现代开发工具和框架:许多现代的前端框架和库(如React, Vue.js, Angular等)都采用了MVVM或类似的模式,这使得开发者可以利用这些工具和框架的优势。 促进模块化开发:MVVM模式鼓励开发者将应用程序分解为更小的、独立的模块,每个模块都有自己的视图模型,这有助于构建大型和复杂的应用程序。
- Model
VIPER (View, Interactor, Presenter, Entity, Router):
- View
- 视图负责显示用户界面和收集用户输入
- 视图不包含任何业务逻辑,只负责展示数据和响应用户交互
- 视图通过协议与呈现器(Presenter)进行交互
- Interactor
- 交互器负责业务逻辑和数据处理
- 它不依赖于视图,可以独立于UI进行开发和测试。
- 交互器通过协议与呈现器(Presenter)和路由器(Router)进行交互。
- Presenter
- 呈现器作为视图和交互器之间的桥梁,负责转换数据并准备数据以供视图显示
- 它不直接与视图交互,而是通过协议与视图和交互器进行通信
- 呈现器从交互器获取数据,处理后发送给视图
- Entity
- 实体是数据模型,代表应用程序中的数据结构
- 实体通常是一个简单的数据结构,不包含任何逻辑
- 实体可以通过交互器与视图模型(ViewModel)进行交互
- Router
- 路由器负责导航逻辑,管理视图之间的跳转
- 它不依赖于视图,可以独立于UI进行开发和测试
- 路由器根据用户交互或业务逻辑的需要,控制视图的展示和隐藏
优缺点
- 优点
- 高度解耦:各个组件之间的耦合度很低,易于独立开发和测试。
- 可维护性:由于组件的独立性,代码的可维护性和可扩展性得到提高。
- 清晰的职责划分:每个组件的职责明确,易于理解和管理。
- 缺点
- 复杂性:架构的复杂性较高,对于小型项目可能过于繁琐。
- 学习曲线:对于不熟悉VIPER的开发者来说,需要时间来学习和适应。
- 性能问题:在某些情况下,组件之间的频繁通信可能会影响性能。
- View
Clean Architecture:
Clean Architecture(干净架构)是一种软件设计模式,由Robert C. Martin(通常称为Uncle Bob)提出。它旨在创建一个以核心业务逻辑为中心,与外部输入输出(如数据库、用户界面、网络等)解耦的系统。Clean Architecture在iOS开发中可以有效地帮助开发者构建可维护、可扩展和可测试的应用程序。下面是Clean Architecture的详细解析:
- 一种不依赖于具体技术栈的架构模式,强调将业务逻辑与UI和数据库等技术细节解耦。
可以看这篇文章Clean Architecture
优点
- 业务逻辑的中心地位:业务逻辑成为应用程序的核心,与外部细节解耦。
- 高度可测试:业务逻辑层可以独立于UI和其他外部依赖进行测试。
- 可维护性:清晰的层次和职责划分使得代码更易于维护和扩展。
- 技术无关性:业务逻辑层不依赖于具体的技术实现,便于技术栈的更换。
缺点
- 学习曲线:对于不熟悉Clean Architecture的开发者,可能需要时间来学习和适应。
- 过度工程:对于小型或简单的项目,Clean Architecture可能会显得过于复杂。
- 性能考虑:在某些情况下,过多的层次和适配器可能会影响应用程序的性能。
组件化架构:
组件化架构是一种软件设计模式,它将应用程序分解为多个独立的组件,每个组件负责应用程序的一部分功能。在iOS开发中,组件化架构可以帮助开发者构建可维护性高、可扩展性强、易于测试的应用程序。以下是组件化架构在iOS开发中的详细解析:
- 组件(Component):
- 组件是自包含的模块,具有特定的功能和职责。
- 组件应该具有清晰的接口,允许其他组件与之交互。
- 模块化(Modularity):
- 模块化是指将应用程序分解为独立的模块,每个模块负责一部分功能。
- 模块之间通过定义良好的接口进行交互,以减少依赖。
- 解耦(Decoupling):
- 解耦是指减少组件之间的相互依赖,使得每个组件可以独立开发和测试。
- 解耦有助于提高代码的可维护性和可扩展性。
- 重用(Reusability):
- 组件化架构鼓励组件的重用,相同的组件可以在不同的项目中使用。
- 重用可以减少开发时间,提高开发效率。
- 独立性(Independence):
- 每个组件应该独立于其他组件,具有自己的生命周期和状态管理。
- 独立性有助于提高组件的可测试性和可维护性。
iOS组件化实现
- 功能模块:
- 将应用程序分解为多个功能模块,如用户认证、数据管理、用户界面等。
- 每个模块作为一个独立的组件,具有自己的业务逻辑和数据管理。
- 服务层(Service Layer):
- 服务层提供了一组服务,如网络请求、数据存储、用户认证等。
- 服务层作为组件之间的桥梁,允许组件之间进行通信和数据交换。
- 接口定义:
- 定义清晰的接口,允许组件之间进行交互。
- 接口可以是协议(Protocols)、抽象类(Abstract Classes)或接口(Interfaces)。
- 依赖注入(Dependency Injection):
- 使用依赖注入来管理组件之间的依赖关系。
- 依赖注入有助于减少组件之间的耦合,提高组件的可测试性和灵活性。
- 组件通信:
- 组件之间通过定义良好的接口进行通信,而不是直接依赖于其他组件的实现。
- 通信可以是同步的,也可以是异步的,取决于组件的职责和需求。
- 组件测试:
- 由于组件的独立性,可以独立测试每个组件。
- 测试可以是单元测试、集成测试或端到端测试,取决于组件的复杂性和职责。
优点
- 可维护性:组件化架构提高了代码的可维护性,因为每个组件都是独立的。
- 可扩展性:添加新功能或修改现有功能变得更加容易,因为组件之间是解耦的。
- 可测试性:独立的组件可以独立进行测试,提高了测试的覆盖率和质量。
- 重用性:相同的组件可以在不同的项目中重用,减少了开发时间和成本。
缺点
- 复杂性:对于小型或简单的项目,组件化架构可能会增加项目的复杂性。
- 学习曲线:对于不熟悉组件化架构的开发者,可能需要时间来学习和适应。
- 性能考虑:在某些情况下,组件之间的通信可能会影响应用程序的性能。
在iOS开发中,组件化架构可以通过各种工具和框架来实现,如Swift Package Manager、CocoaPods等。通过采用组件化架构,开发者可以构建出结构清晰、易于维护和扩展的应用程序。
- 组件(Component):
Reactive Programming:
- 响应式编程,应用程序的组件对数据流和变化做出响应。
设计模式
iOS 开发中常用的设计模式主要包括以下几种:
- 模型-视图-控制器(MVC)模式:
- 模型(Model):负责应用程序的数据和业务逻辑。
- 视图(View):负责显示数据(即用户界面),通常是 UIView 或其子类的实例。
- 控制器(Controller):作为模型和视图之间的中介,处理用户输入并调用模型和视图更新。
- 模型-视图-视图模型(MVVM)模式:
- 模型(Model):与 MVC 中的模型类似,负责数据和业务逻辑。
- 视图(View):负责展示数据,通常是通过数据绑定与视图模型交互。
- 视图模型(ViewModel):是 MVC 中控制器的衍生,它包含了视图所需的所有数据和命令,通过数据绑定与视图连接。
- 单例(Singleton)模式:
- 确保一个类只有一个实例,并提供一个全局访问点。在 iOS 中,单例模式常用于管理共享资源,如通知中心或配置管理。
- 代理(Delegate)模式:
- 代理模式允许一个对象将某些任务委托给另一个对象。在 iOS 开发中,代理模式广泛用于处理事件和回调,如 UITableViewDataSource 和 UITableViewDelegate。
- 观察者(Observer)模式:
- 观察者模式允许对象在状态变化时通知其他对象。在 iOS 中,这个模式通过 KVO(键值观察)和 Notifications 实现。
- 工厂(Factory)模式:
- 工厂模式用于创建对象,而不需要将如何创建的细节暴露给客户端。在 iOS 中,Storyboard 和 XIB 文件可以看作是工厂模式的实现,用于创建视图控制器和视图。
- 策略(Strategy)模式:
- 策略模式定义了一系列算法,并将每个算法封装起来,使它们可以互换。在 iOS 中,这个模式可以用来实现不同的交互逻辑或动画效果。
- 命令(Command)模式:
- 命令模式将请求封装为一个对象,从而使你可用不同的请求对客户进行参数化。在 iOS 中,这个模式可以用于封装用户的动作,如撤销和重做操作。
- 适配器(Adapter)模式:
- 适配器模式允许将一个类的接口转换成客户希望的另一个接口。在 iOS 中,这个模式可以通过类别(Categories)或协议(Protocols)来实现,以适配不同的接口。
- 组合(Composite)模式:
- 组合模式允许你以树状结构的形式组合对象,表示部分-整体的层次结构。在 iOS 中,这个模式可以通过 UIView 的层次结构来实现复杂的用户界面。
敏捷开发
敏捷开发(Agile Development)是一种以人为核心、迭代、循序渐进的软件开发方法论。敏捷开发流程强调在整个开发过程中的适应性和灵活性,以及快速和高效地交付价值给客户。以下是敏捷开发流程的详细解析:
1
2
3
4
什么是敏捷开发?
在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。
在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。
简单地来说,敏捷开发并不追求前期完美的设计、完美编码,而是力求在很短的周期内开发出产品的核心功能,尽早发布出可用的版本。然后在后续的生产周期内,按照新需求不断迭代升级,完善产品。
敏捷宣言(Agile Manifesto)
敏捷开发的核心理念在2001年由17位软件开发者提出的敏捷宣言中有所体现,主要包括以下四个价值观:
- 个体和互动 高于流程和工具
- 可工作的软件 高于详尽的文档
- 客户合作 高于合同谈判
- 响应变化 高于遵循计划
敏捷开发方法论
有几种流行的敏捷开发方法论,包括但不限于:
- Scrum:一个包括角色(如Scrum Master、Product Owner)、仪式(如Sprint Planning、Daily Stand-up)和工件(如Product Backlog)的框架。
- 极限编程(XP):强调编程实践,如结对编程、持续集成、
TDD测试驱动开发和FDD功能驱动开发。 - 看板(Kanban):使用看板板来可视化工作流程,管理进行中的任务。
Scrum
SCRUM则是一种开发流程框架,也可以说是一种套路。SCRUM框架中包含三个角色,三个工件,四个会议:
1
2
3
4
5
6
7
8
Sprint:冲刺周期,通俗的讲就是实现一个“小目标”的周期。一般需要2-6周时间。
User Story:用户的外在业务需求。拿银行系统来举例的话,一个Story可以是用户的存款行为,或者是查询余额等等。也就是所谓的小目标本身。
Task:由User Story 拆分成的具体开发任务。
Backlog:需求列表,可以看成是小目标的清单。分为Sprint Backlog和Product Backlog。
Daily meeting(Stand up):每天的站会,用于监控项目进度。有些公司直接称其为Scrum。
Sprint Review meeting: 冲刺评审会议,让团队成员们演示成果。
Sprint burn down:冲刺燃尽图,说白了就是记录当前周期的需求完成情况。
Rlease:开发周期完成,项目发布新的可用版本。
SCRUM的工作流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
迭代开发 Iterative Development
- 开发过程被分解为一系列短期(通常是1到4周)的迭代周期,称为Sprint或迭代。
产品待办列表 Product Backlog
- 产品负责人(Product Owner)维护一个优先级列表,列出了所有需要开发的功能和需求。
待办列表细化 Backlog Refinement
- 团队定期审查和优先排序产品待办列表,确保列表反映了客户的需求。
迭代计划 Sprint Planning
- 在每个迭代开始时,团队选择一定量的产品待办列表项,计划在迭代中完成。
日常沟通 Daily Stand-up
- 团队成员每天进行短暂的站立会议,讨论进度、计划和阻碍。
适应性计划
敏捷开发鼓励在项目过程中根据反馈和变化来调整计划,而不是严格遵循预先定义的计划。(加ticket)
开发人员互动:
敏捷开发重视团队成员之间的面对面交流,认为这比流程和工具更为重要。
工作软件:(Jira + Slack + Bitrise) (飞书、钉钉)
敏捷开发认为可以工作的软件是进度的主要衡量标准,而不是详尽的文档。
持续交付 Continuous Delivery (Jira + Slack + Bitrise)
- 经常性地向客户交付可工作的软件,通常每个迭代结束时都有交付。
测试驱动开发 Test-Driven Development, TDD
- 先编写测试用例,然后编写满足测试的代码,确保代码质量。
客户反馈 Customer Feedback (UAT Feedback) ---- UAT User Acceptance Testing
- 通过原型、演示和交付的软件,收集客户反馈,并将其整合到开发过程中。
回顾 Retrospectives
- 每个迭代结束时,团队会进行回顾会议,讨论哪些做得好,哪些需要改进。
敏捷开发与Devops
Devops是Development和Operations的合成词,其目标是要加强开发人员、测试人员、运维人员之间的沟通协调。如何实现这一目标呢?需要我们的项目做到持续集成、持续交付、持续部署。
敏捷 12 原则
1
2
3
4
5
6
7
8
9
10
11
12
1.我们的最高目标是满足客户通过尽早和持续地交付有价值的软件来满足客户。
2.欢迎需求变更,即使在开发后期也应如此。敏捷过程利用变更为客户竞争优势。
3.经常交付可工作的软件,交付周期从几周到几个月,以较短的周期为佳。
4.业务人员和开发者必须每天一起工作。
5.构建项目围绕有激励的个体。给他们所需的环境和支持,并且信任他们完成工作。
6.面对面的沟通是信息传递效率和效果最好的方式。尽管这不可替代,也必须足够使用其他方式。
7.可用的工作软件是进度的主要度量。
8.敏捷过程提倡可持续的开发。赞助人、开发者和用户应该能够无限期地保持恒定的开发速度。
9.持续关注技术卓越和良好设计可以增强敏捷性。
10.简洁——通过尽可能少的工作量做到最大化的工作量——是本质。
11.最佳的架构、需求和设计来自于自组织的团队。
12.团队定期反思如何更有效率,并相应地调整其行为。
敏捷开发的挑战
- 需要团队成员的高度协作和沟通。
- 需要客户或利益相关者的持续参与和反馈。
- 需要团队成员具备快速学习和适应变化的能力。
敏捷开发的益处
- 提高了对客户需求变化的响应能力。
- 增强了团队的协作和沟通。
- 减少了项目失败的风险。
- 提供了更高质量的软件解决方案。
排序Sorting
冒泡排序
1
2
3
4
5
6
7
8
9
10
11
12
13
// 冒泡排序
// 降序
// 泛型比较大小: Comparable
// 时间平均复杂度:O(n^2) 最坏复杂度:O(n^2) 最好复杂度: O(n) 空间复杂度: O(1) 稳定
func bubleSorting<T: Comparable>(_ array: inout [T]) {
for i in 0..<array.count {
for j in 0..<array.count - 1 - i {
if array[j] < array[j + 1] {
swaps(&array, before: j, after: j + 1)
}
}
}
}
插入排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 插入排序
// 降序
// 时间平均复杂度:O(n^2) 最坏复杂度:O(n^2) 最好复杂度: O(n) 空间复杂度: O(1) 稳定
func insertSorting<T: Comparable>(_ array: inout [T]) {
for i in 1..<array.count {
for j in 0..<i {
let k = i - j
guard k > 0, array[k - 1] < array[k] else {
break
}
swaps(&array, before: k - 1, after: k)
}
}
}
选择排序
1
2
3
4
5
6
7
8
9
10
11
12
// 选择排序
// 降序
// 时间平均复杂度:O(n^2) 最坏复杂度:O(n^2) 最好复杂度: O(n^2) 空间复杂度: O(1) 不稳定
func selectionSorting<T: Comparable>(_ array: inout [T]) {
for i in 0..<array.count {
for j in i..<array.count - 1 {
if array[i] < array[j + 1] {
swaps(&array, before: i, after: j + 1)
}
}
}
}
交换两个数
1
2
3
func swaps<T>(_ array: inout [T], before b: Int, after a: Int) {
(array[b], array[a]) = (array[a], array[b])
}
快速排序
1
2
3
4
5
6
7
8
9
10
11
12
13
// 快速排序
// 降序
// 时间平均复杂度:O(nlog2^n) 最坏复杂度:O(n^2) 最好复杂度: O(nlog2^n) 空间复杂度: O(nlog2^n) 不稳定
func quickSorting<T: Comparable>(_ array: [T]) -> [T] {
guard array.count > 1 else {
return array
}
let pivot = array[array.count / 2]
let less = array.filter({ $0 > pivot })
let middle = array.filter({ $0 == pivot })
let greater = array.filter({ $0 < pivot })
return quickSorting(less) + middle + quickSorting(greater)
}
Unit Test
1
2
3
4
5
6
7
8
let viewModel = SortingViewModel()
func testBubleSorting() {
let desArray = [8, 7, 6, 5, 4, 3, 2, 1]
var array = [1, 3, 5, 2, 4, 8, 6, 7]
viewModel.bubleSorting(&array)
XCTAssertEqual(desArray, array)
}
并发
Sendable 和 @Sendable 提供了一种在并发代码中明确声明类型和闭包是否是“可发送的”的方式,从而帮助开发者编写更安全、更可靠的并发代码.
async let 是 Swift 中的一种便捷方式,允许我们在异步上下文中方便地等待异步操作完成,并直接处理结果。使用async let时,编译器会自动生成一个临时的 Task 来处理异步操作,并在该操作完成后将结果赋给相应的变量。
Actor 是一种并发编程模型,用于管理共享状态。Actor 允许你定义一个包含异步方法和属性的实体,这些方法和属性只能由一个线程同时访问。避免了常见的并发问题,如数据竞争和死锁。
Async和Await是用于异步编程的关键字。它们使得编写和管理异步代码更加简单和直观,提高复杂异步代码的可读性。
- Async:
async关键字用于标记一个函数、闭包或方法是一个异步操作。使用async关键字声明的函数可以在其中使用await来等待其他异步操作的结果,而不会阻塞当前线程。 - Await:
await关键字用于暂停当前异步函数的执行,等待另一个异步操作的完成,并且获取其结果。这样可以让程序在等待异步操作的同时继续执行其他任务,提高了并发性和响应性。
崩溃和异常
App 出现崩溃(crash)原因,是因为违反iOS系统运行规则导致的,产生crash的三种类型:
内存引发闪退
- 无效的内存访问
- 内存访问越界
- 运行时方法调用不存在
- 解引用指向无效内存地址的指针
- 跳转到无效地址的指令
响应超时
启动、挂起、恢复、结束等事件响应不及时
触发Watchdog机制
Watchdog 机制是为了防止一个应用占用过多系统资源,如果超出了该场景规定的运行时间,“看门狗”就会强制kill掉这个应用,在 crashlog 会看到 “0x8badf00d”的错误代码。
Mach 异常和 Unix 信号
在常见的异常崩溃信息中,经常会看到有
Exception Type: EXC_BAD_ACCESS (SIGSEGV)这样的字段和内容,EXC_BAD_ACCESS和SIGSEGV,分别是指 Mach 异常和 Unix 信号。这个 Exception Type 意思是 Mach 层的异常 EXC_BAD_ACCESS 被转换成 SIGSEGV 信号并传递给出错的线程。SIGILL:程序非法指令信号,通常是因为可执行文件本身出现错误,或者试图执行数据段。堆栈溢出时也有可能产生该信号。SIGABRT:程序中止命令中止信号,调用 abort 函数时产生该信号。SIGBUS:程序内存字节地址未对齐中止信号,比如访问一个 4 字节长的整数,但其地址不是 4 的倍数。SIGFPE:程序浮点异常信号,通常在浮点运算错误、溢出及除数为等算术错误时都会产生该信号。SIGKILL:程序结東接收中止信号,用来立即结東程序运行,不能被处理、阻塞和忽略。SIGSEGV:程序无效内存中止信号,即试图访问未分配的内存,或向没有写权限的内存地址写数据。SIGPIPE:程序管道破裂信号,通常是在进程间通信时产生该信号。SIGSTOP:程序进程中止信号,与 SIGKILLー样不能被处理、阻塞和忽略。
异常监控系统
1
2
3
4
5
6
7
它的主要功能:
实时监控SDK业务异常
汇总包体崩溃排重与聚合后的数据
统计影响设备数
上报崩溃日志
收集iOS系统向上兼容性问题
监控客户端请求的网络问题
内存泄漏
内存泄漏(memory leak):是指申请的内存空间使用完毕之后未回收。 一次内存泄露危害可以忽略,但若一直泄漏,无论有多少内存,迟早都会被占用光,最终导致程序crash。
内存溢出(out of memory):是指程序在申请内存时,没有足够的内存空间供其使用。 通俗理解就是内存不够用了,通常在运行大型应用或游戏时,应用或游戏所需要的内存远远超出了你主机内安装的内存所承受大小,就叫内存溢出。最终导致机器重启或者程序crash。
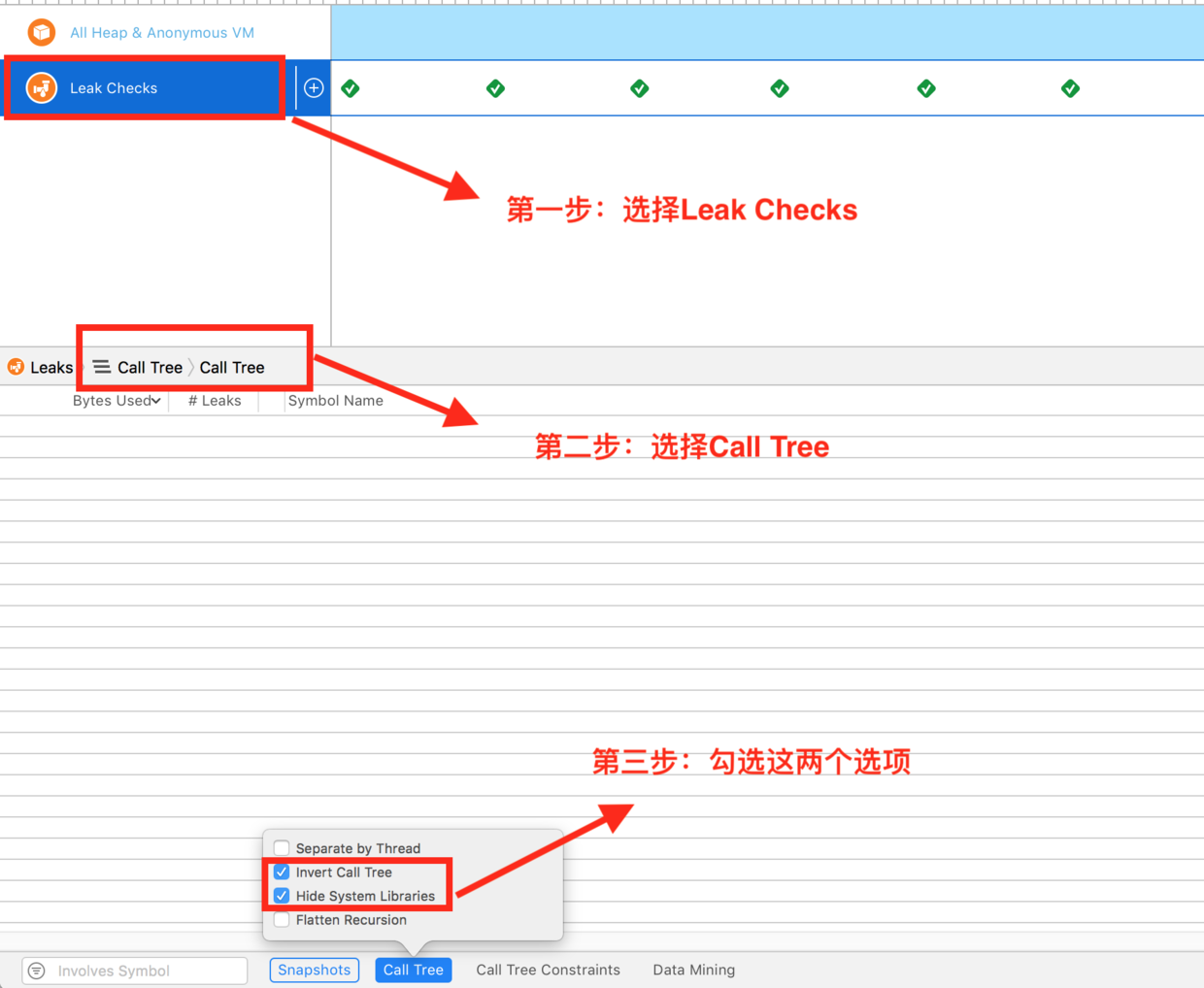
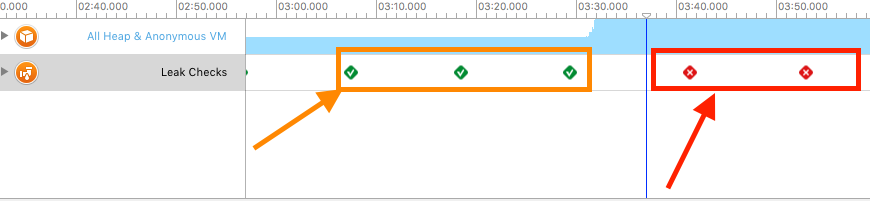
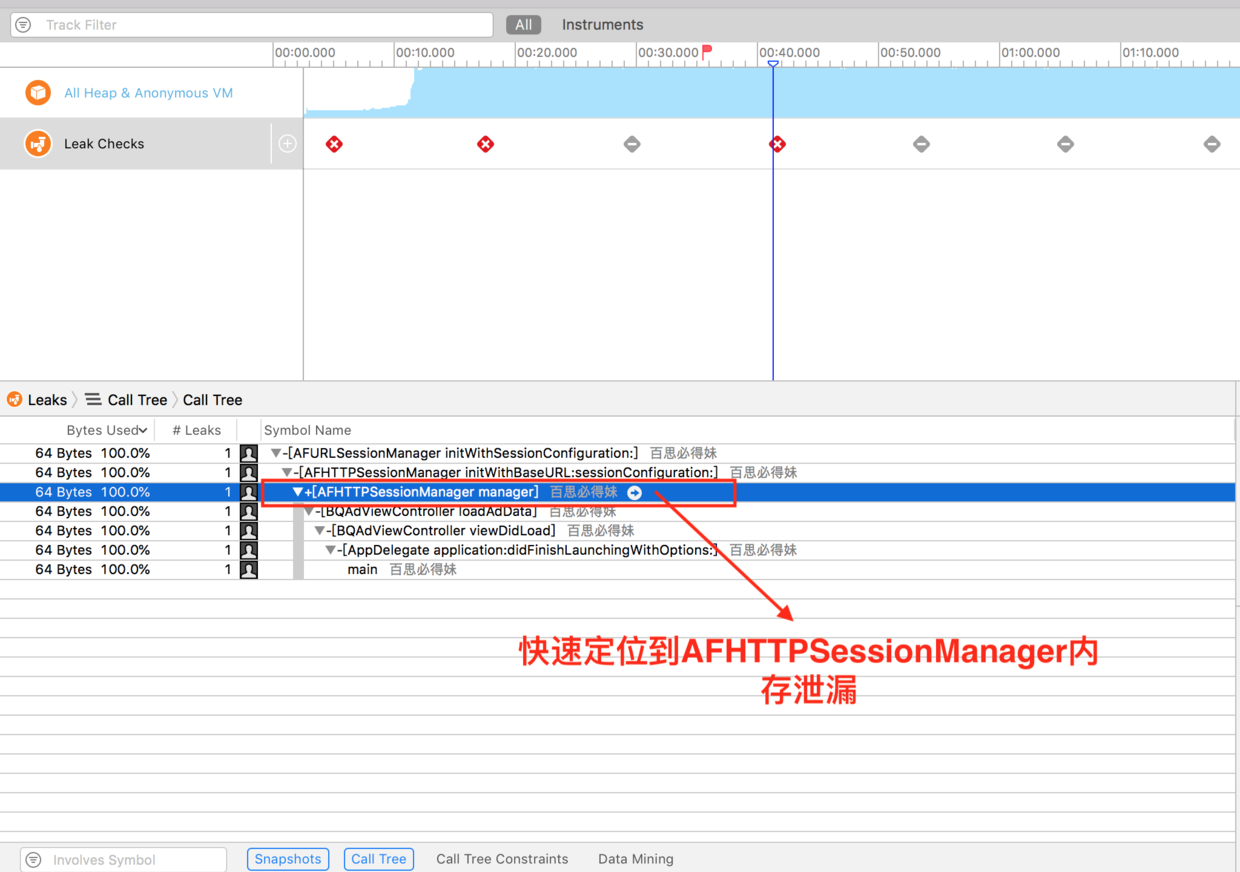
检查我们的App有没有内存泄漏,并且快速定位到内存泄漏的代码。目前比较常用的内存泄漏的排查方法有两种,都在Xcode中可以直接使用:
第一种:静态分析方法(
Analyze)- 通过Xcode打开项目,然后点击Product->Analyze,开始进入静态内存泄漏分析。
![ddd]()
第二种:动态分析方法(
Instrument工具库里的Leaks)。一般推荐使用第二种。静态内存泄漏分析不能把所有的内存泄漏排查出来,因为有的内存泄漏发生在运行时,当用户做某些操作时才发生内存泄漏。这是就要使用动态内存泄漏检测方法了
- 在ARC环境下,导致内存泄漏的根本原因是代码中存在循环引用,从而导致一些内存无法释放,最终导致dealloc()方法无法被调用。
- ViewController中存在NSTimer
- ViewController中的代理delegate
- ViewController中Block
- 如果
block被当前ViewController(self)持有,这时,如果block内部再持有ViewController(self),就会造成循环引用
- 如果
- 在ARC环境下,导致内存泄漏的根本原因是代码中存在循环引用,从而导致一些内存无法释放,最终导致dealloc()方法无法被调用。

性能优化
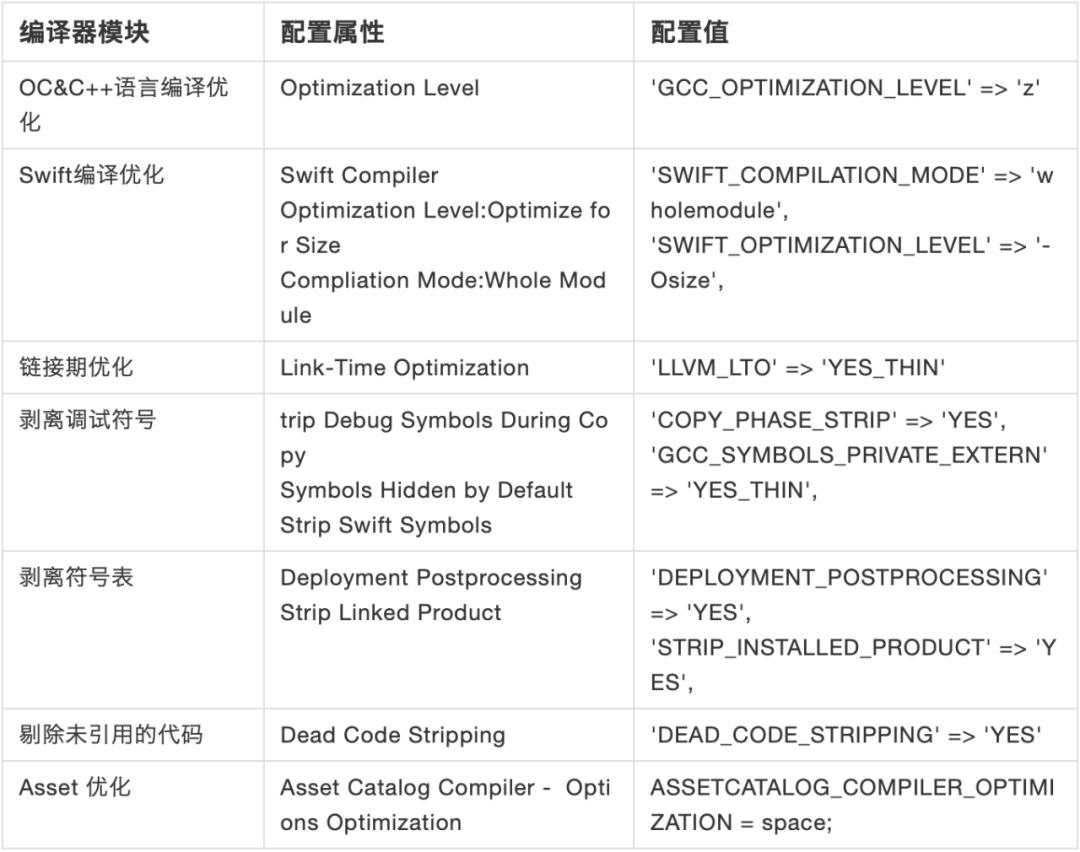
1.包大小优化
- 资源优化
- 资源是指plist、js、css、json、端智能模型文件等
- 大资源优化、无用配置文件、重复资源
- 工程架构优化
- 防劣化机制、Xcode升级
- 防劣化机制: 良好的防劣化机制解决的是增量问题,以避免包体积无序增长
- 图片优化
- 无用图片优化
- Asset Catalog优化
- HEIC图片优化
- Webp 压缩
编译优化
![00]()
代码优化
- 无用类瘦身、无用模块瘦身、无用方法瘦身、精简重复代码、工具类瘦身
- 动态库 -> 静态库
1.启动时间优化
App 的启动时间,指的是从用户点击 App 开始,到用户看到第一个界面之间的时间;也就是 didBecomeActive 的时候或者 rootVC 的 viewDidAppear 的时候。启动过程:
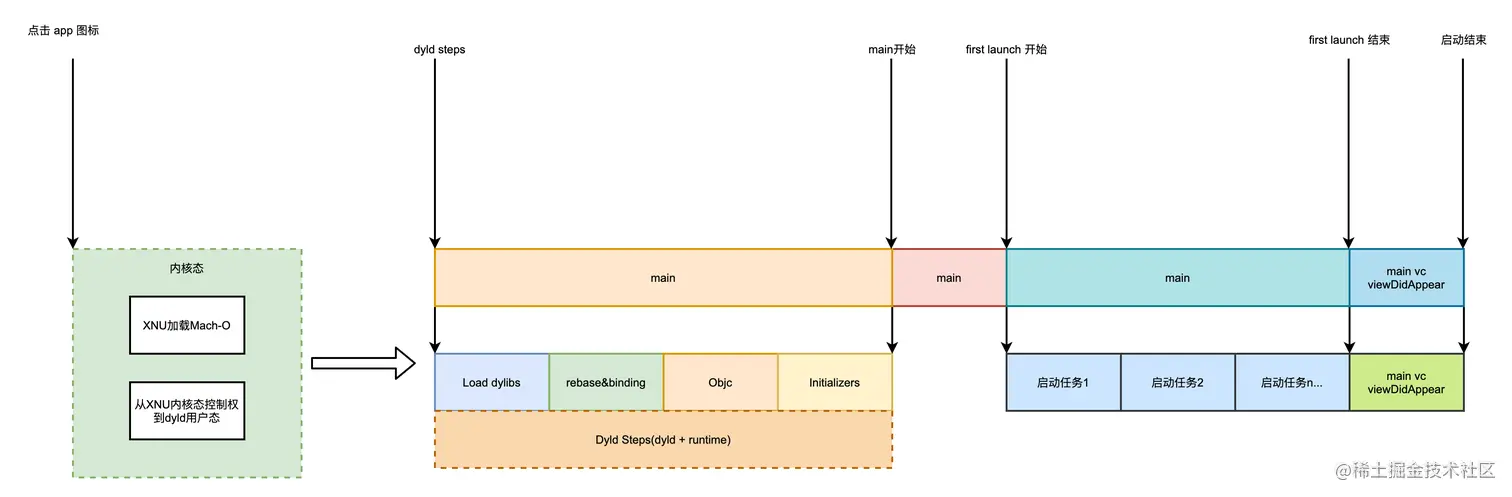
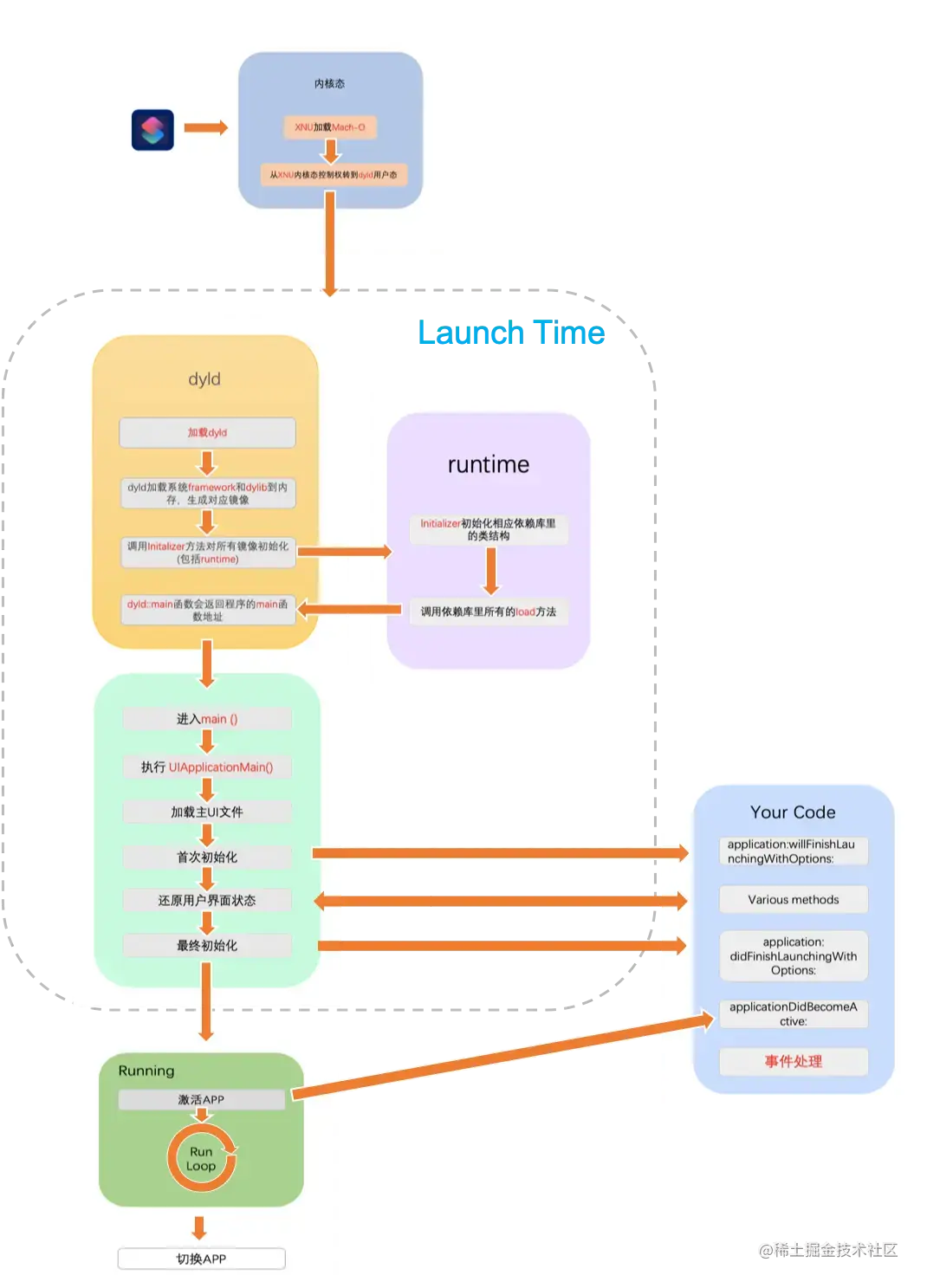
冷启动耗时
主要分为了 pre-main 阶段和 main() 阶段.
pre-main阶段耗时- dylib loading time: 动态库载入耗时
- rebase/binding time: 修正符号和绑定符号的耗时
- image list 打印的项目的地址 + linkMap 中的 _main 的 Address Size 就是实际的 main 函数的内存地址也就是准确地址
- iOS 系统在 App 的可执行文件中,添加一个符号,等到运行的时候,由系统去绑定我们的符号,找到真正的外部函数。
ObjC setup time:Objc 类的注册、category 的定义插入方法列表、保证 selector 唯一的耗时initializer time:Objc 类的 +load()、C++ 的构造函数属性函数的构造函数、C++ 的静态全局变量创建的耗时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
/// 优化 1.动态库处理: 删除/合并动态库,或者动态库转成静态库,并减少使用Embedded Framework。 2.清理无用类、分类、方法. AppCode 里的 Code->Inspect Code 进行静态分析,二次确认无用后删除 3.避免在+load方法中执行耗时操作,使用+initialize代替。 4.减少非基本类型的C++静态全局变量的个数。 5.二进制重排(Clang 插桩) 6.1 可以通过添加环境变量可以打印出APP的启动时间分析(Edit scheme -> Run -> Arguments) 冷启动的三大阶段:1.dyld 2.runtime 3.main 6.1.1 dyld:Apple的动态连接器,可以用来装在Mach-0文件 优化: 减少动态库,合并一些动态库 减少Objc类,分类的数量,减少Selector数量,定期清理没有使用的类,分类 减少C++虚函数数量 swift尽量使用struct代替类 6.1.2 runtime: 调用map_images进行可执行文件内容的解析和处理 在load_images中调用call_load_methods,调用所有Class和Category的+load方法 进行各种objc结构的初始化(注册Objc类,初始化类对象等) 通过C++静态初始化器和_attribute_((constructor))修饰的函数 到此为止,可执行文件和动态库中的所有符号(Class,Protocol,Selector,IMP...)都已经按格式成功加载到内存中,被runtime所管理 优化:用+initialize+单例代替+load 6.1.3 调用main函数 优化:在不影响用户体验的前提下,尽可能将一些操作延迟,不要全部放在finishLaunching中 6.1.4 二进制重排推荐文章:juejin.cn/post/684490…
main()阶段耗时- 主要是
application:didFinishLaunchingWithOptions:中的 SDK 初始化、业务注册、各个模块业务处理等耗时
1 2 3 4 5
/// 优化 1.不重要的业务后移(启动项后置) 2.删除不必要的初始化代码。 3.延迟加载不必要的模块和功能。 4.使用异步加载和懒加载来提高启动速度。
- 主要是
监控工具
1 2
Xcode Instruments:Xcode自带的性能分析工具,可以使用Time Profiler和System Trace等工具来监控应用程序的启动时间和性能。 DYLD_PRINT_STATISTICS:通过设置环境变量DYLD_PRINT_STATISTICS或DYLD_PRINT_STATISTICS_DETAILS,可以在Xcode中查看应用程序启动过程中各个阶段的耗时统计信息。
卡顿优化
卡顿的概念:
- FPS:Frame Per Second,表示每秒渲染的帧数,通过用于衡量画面的流畅度,数值越高则表示画面越流畅。
- CPU:负责对象的创建销毁、对象属性的调整、布局计算、文本计算、和排版、图片的格式转换和解码、图像的绘制(Core Graphics)。
- GPU:负责纹理的渲染(将数据渲染到屏幕)。
- 垂直同步技术:让CPU和GPU在收到vSync信号后开始准备数据,防止撕裂感和跳帧,即保证每秒输出的帧数不高于屏幕显示的帧数。
- 双缓冲技术:iOS是双缓冲机制,前帧缓存和后帧缓存,cpu计算完GPU渲染后放入缓冲区中,当gpu下一帧已经渲染完放入缓冲区,且视频控制器已经读完前帧,GPU会等待vSync(垂直同步信号)发出后,瞬间切换前后帧缓存,并让cpu开始准备下一帧数据。
图像显示:
图像的显示可以理解为先经过CPU的计算、排版、编解码等操作,然后交有GPU去完成渲染放入缓冲中,当视频控制器受到vSync时会从缓冲中读取已经渲染完成的帧并显示到屏幕上。
屏幕显示的过程:CPU计算显示内容,例如视图创建、布局计算、图片解码、文本绘制等;接着CPU将计算好的内容提交到GPU进行合成、渲染。然后GPU把渲染结果提交到帧缓冲区,等待VSync信号到来时显示到屏幕上。如果此时下一个VSync信号到来时,CPU或者GPU没有完成相应的工作时,那一帧就会丢失,就会看到屏幕卡顿。
按照60FPS的帧率,每隔16ms就会有一次VSync信号,1秒是1000ms,1000/60 = 16
卡顿的原因:
iOS默认刷新频率是60HZ,所以GPU渲染只要达到60fps就不会产生卡顿。如果在60fps(16.67ms)内没有准备好下一帧数据就会使画面停留在上一帧。
只要能使CPU的计算和GPU的渲染能在规定时间内完成,就不会出现卡顿。所以目标是减少CPU和GPU的资源消耗。
卡顿造成的原因是CPU和GPU导致的掉帧引起的:
- 主线程在进行大量I/O操作:直接主线程写入大量数据
- 主线程进行大量计算:主线程进行大量复杂的计算
- 大量UI绘制:界面过于复杂,绘制UI需要大量的时间
- 主线程在等锁
优化卡顿:
CPU:
减少计算,减少耗时操作
- 提前计算好布局,列表页高度在请求完成数据后,就计算好高度,显示时直接使用。
- 尽量使用轻量级的对象,比如用不到事件处理的地方使用CALayer代替UIView
- hook setNeedsLayout、setNeedDisplay、setNeedsDisplayInRect方法,保证方法在主线程运行
- 查找因重复执行导致卡顿的方法,比如多个地方监听同一个通知,通知中执行多次的清除缓存的方法
- 保证后台运行时,不调用接口
- 把耗时的操作放到子线程
- 文本处理(尺寸计算、绘制、CoreText和YYText)
- 计算文本宽高boundingRectWithSize:options:context:和文本绘制drawWithRect:options:context放在子线程操作。
- 使用CoreText自定义文本空间,在创建对象过程中可以缓存宽高等信息,避免像UILabel/UITextView需要多次计算(调整和绘制都要计算一次),且CoreText直接使用了CoreGraphics占用内存小,效率高。(YYText)
- 图片解码:当使用UIImage或者CGImageSource创建图片时,图片数据并不会立即解码。图片设置到UIImageView或CALayer.content中,并且CALayer被提交到GPU前,CGImage中到数据才会得到解码,这一步是发生在主线程的,并且不可避免。SDWebImage处理方式:在后台线程先把图片绘制到CGBitmapmapContext中,然后直接从Bitmap创建图片。
GPU:
减少渲染
- 避免短时间内大量图片的显示,尽可能将多张图片合成一张显示
- GPU能处理的最大纹理尺寸是4096*4096,一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸
- GPU会将多个视图混合在一起再去显示,混合的过程中会消耗CPU资源,尽量减少视图数量和层次
- 减少透明的视图(alpha < 1),不透明的设置opacity为YES,GPU就不会进行alpha通道的合成
- 尽量避免出现离屏渲染
离屏渲染:
离屏渲染是指GPU在当前屏幕缓冲区(Frame Buffer)以外开辟一块新的缓冲区(Off- Screen Buffer)进行渲染工作。在当前屏幕缓冲区之外的渲染称之为离屏渲染。
离屏渲染消耗性能的原因,在于需要创建新的缓冲区,并且在渲染的整个过程中,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕,造成了资源到极大消耗。
一些会触发离屏渲染的操作:
- 光栅化,layer.shouldRasterize = YES
- 遮罩,layer.mask
- 圆角,同时设置layer.masksToBounds=YES、layer.cornerRadius大于0,考虑通过CoreGraphics绘制裁剪圆角,或者直接使用圆角图片
- 阴影
如何避免离屏渲染:
1
2
3
4
5
1.避免同时设置 layer.cornerRadius 和 layer.masksToBounds = YES,即设置圆角的同时又允许切割圆角;
2.需要使用圆角图片时,预先用 CoreGraphics 切好;
3.阴影使用 shadowPath ;
4.需要mask的情况下,可以使用自定义 UIView;
5.需要进行模糊处理的时候尽量不用 UIVisualEffectView ,使用CoreImage提供的方法或者是Accelerate.framework。
监控工具:
- Instruments:Xcode自带的性能分析工具,可以监控CPU、内存、网络等性能指标,帮助定位卡顿问题 [2].
- FPS监控:通过在App中添加FPS监控代码,可以实时监测帧率,判断是否存在卡顿.
- 卡顿检测工具:如Facebook的Chisel、Tencent的GT等,可以监测主线程卡顿情况,并提供详细的卡顿堆栈信息
iOS 保持界面流畅的技巧
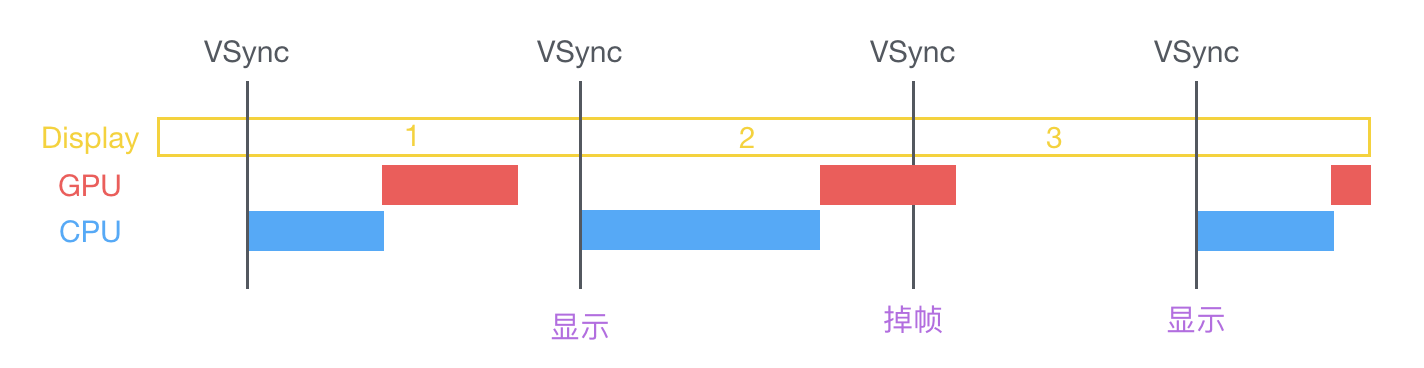
CPU 和 GPU 不论哪个阻碍了显示流程,都会造成掉帧现象。所以开发时,也需要分别对 CPU 和 GPU 压力进行评估和优化。
CPU 资源消耗原因和解决方案
- 对象创建
- 对象的创建会分配内存、调整属性、甚至还有读取文件等操作,比较消耗 CPU 资源
- 尽量用轻量的对象代替重量的对象,可以对性能有所优化。比如 CALayer 比 UIView 要轻量许多
- 通过 Storyboard 创建视图对象时,其资源消耗会比直接通过代码创建对象要大非常多,Storyboard 并不是一个好的技术选择。
- 对象调整
- 对象的调整也经常是消耗 CPU 资源的地方,当视图层次调整时,UIView、CALayer 之间会出现很多方法调用与通知,所以在优化性能时,应该尽量避免调整视图层次、添加和移除视图。
- 对象销毁
- 布局计算
- 视图布局的计算是 App 中最为常见的消耗 CPU 资源的地方,如果能在后台线程提前计算好视图布局、并且对视图布局进行缓存,那么这个地方基本就不会产生性能问题了。
- Autolayout
- Autolayout 是苹果本身提倡的技术,在大部分情况下也能很好的提升开发效率,但是 Autolayout 对于复杂视图来说常常会产生严重的性能问题
- 文本计算
- 文本渲染
- 图片的解码
- 图像的绘制
GPU 资源消耗原因和解决方案
接收提交的纹理(Texture)和顶点描述(三角形),应用变换(transform)、混合并渲染,然后输出到屏幕上。通常你所能看到的内容,主要也就是纹理(图片)和形状(三角模拟的矢量图形)两类。
- 纹理的渲染
- 视图的混合 (Composing)
- 图形的生成。
AsyncDisplayKit
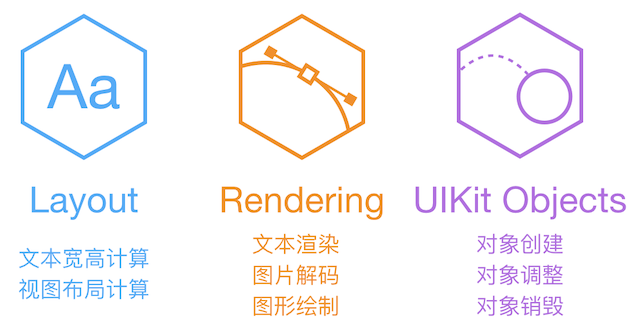
ASDK 认为,阻塞主线程的任务,主要分为上面这三大类。文本和布局的计算、渲染、解码、绘制都可以通过各种方式异步执行,但 UIKit 和 Core Animation 相关操作必需在主线程进行。ASDK 的目标,就是尽量把这些任务从主线程挪走,而挪不走的,就尽量优化性能。
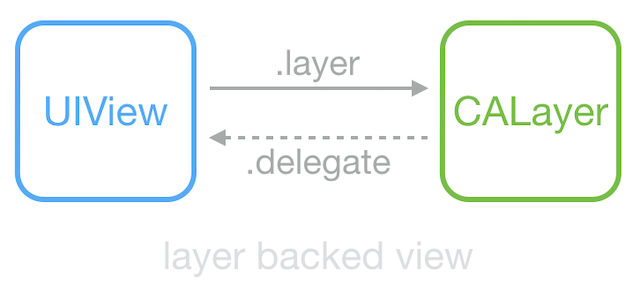
View 持有 Layer 用于显示,View 中大部分显示属性实际是从 Layer 映射而来;当其属性改变、动画产生时,View 能够得到通知。UIView 和 CALayer 不是线程安全的,并且只能在主线程创建、访问和销毁。
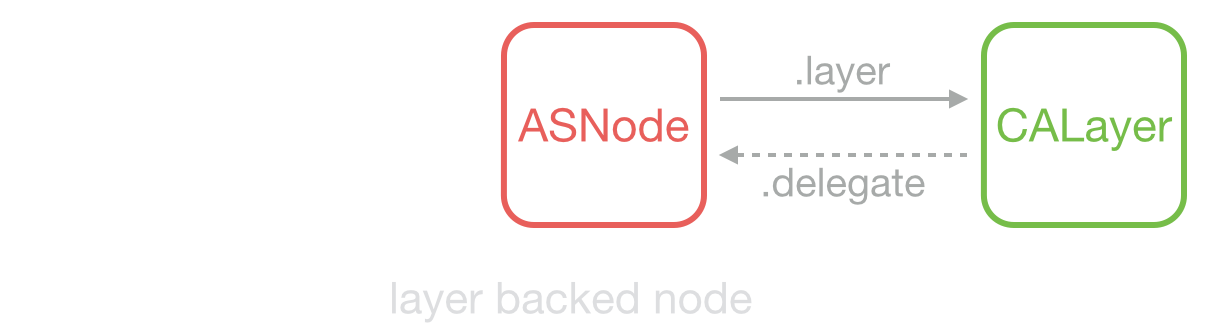
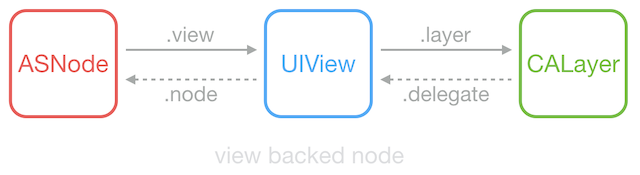
ASDK 为此创建了 ASDisplayNode 类,包装了常见的视图属性(比如 frame/bounds/alpha/transform/backgroundColor/superNode/subNodes 等),然后它用 UIView->CALayer 相同的方式,实现了 ASNode->UIView 这样一个关系。
ASDK 把布局计算、文本排版、图片/文本/图形渲染等操作都封装成较小的任务,并利用 GCD 异步并发执行。如果开发者使用了 ASNode 相关的控件,那么这些并发操作会自动在后台进行,无需进行过多配置。
性能优化技巧
- 预排版
- 当获取到 API JSON 数据后,把每条 Cell 需要的数据都在后台线程计算并封装为一个布局对象 CellLayout。
- 预渲染
- 当头像下载下来后,我会在后台线程将头像预先渲染为圆形并单独保存到一个 ImageCache 中去。为了避免离屏渲染,你应当尽量避免使用 layer 的 border、corner、shadow、mask 等技术,而尽量在后台线程预先绘制好对应内容。
- 异步绘制
- 更高效的异步图片加载
- FPS 指示器:FPSLabel
生命周期
iOS App 的生命周期:
- Not Running(未运行):当应用被终止或者还没有被启动时,处于这个状态。
- Inactive(非活跃):应用正在前台运行,但是无法接收事件响应,比如来电提醒等情况。一般不会停留在这个状态很长时间。
- Active(活跃):应用在前台运行并且接收事件响应。
- Background(后台):应用在后台运行并且可以执行代码。在进入后台之前,系统会发送一个通知给应用,开发者有一定时间来保存数据和状态。
- Suspended(挂起):应用在后台,但是没有执行代码。系统可能会在内存不足的情况下终止挂起的应用。
**UIViewController生命周期: **
当进入一个视图控制器时:
+(instancetype)initialize;-(instancetype)init;-(void)loadView;-(void)viewDidload;-(void)viewWillAppear;-(void)viewWillLayoutSubviews-(void)viewDidLayoutSubviews-(void)viewDidAppear;
当退出一个视图时:
-(void)viewWillDisappear;-(void)viewDidDisappear;-(void)dealloc;
UIView的生命周期
- init(frame:):在代码中初始化 UIView 时会调用这个方法,设置视图的大小和位置。
- initWithCoder::从 xib 或 storyboard 文件加载视图时会调用这个方法。
- layoutSubviews:当视图的 bounds 改变时,会调用这个方法重新布局子视图。
- didMoveToSuperview:当视图被添加到父视图上时会调用这个方法。
- willMove(toSuperview:):在视图即将被添加到父视图时调用。
- didMoveToWindow:当视图被添加到窗口上时调用。
- willMove(toWindow:):在视图即将被添加到窗口时调用。
- layoutIfNeeded():强制视图立即布局子视图。
数据持久化
在iOS开发中,数据持久化是指将应用程序中的数据保存到本地存储介质中,以便在应用退出后或重启时能够恢复数据。以下是iOS中常用的数据持久化方法:
- UserDefaults:UserDefaults是一个简单的键值对存储容器,用于存储少量用户偏好设置或配置数据。适用于存储用户设置、应用程序状态等轻量级数据。
- Property List (Plist):Property List 是一种基于 XML 的文件格式,可以用来存储各种数据类型。适用于存储简单数据结构,如数组、字典等。
- Archiving(归档):通过实现NSCoding协议,可以将自定义对象序列化为二进制数据,并进行存储。适用于存储自定义对象或复杂数据结构。
- Core Data:Core Data 是一个面向对象的数据持久化框架,提供了数据模型、对象图管理和数据存储功能。适用于较复杂的数据模型和关系数据库存储需求。
- SQLite:SQLite 是一个轻量级的关系型数据库引擎,iOS提供了SQLite C接口,可以用来操作 SQLite 数据库。适用于需要更灵活的查询和数据处理的场景。
- Realm:Realm 是一个跨平台的移动数据库解决方案,提供了高性能、易用的 API 接口,支持对象映射、事务处理等功能。适用于需要高性能数据存储与查询的场景。
- File System:直接将数据存储为文件形式,使用沙盒目录中的 Documents 目录或其他目录来保存数据文件。适用于存储大量文件或复杂数据结构。
- SwiftData: 是 Apple 在 WWDC 2023 上推出的一个新框架,专门用于 iOS 应用中的持久性存储。这个框架的目的是为了简化 Core Data 的使用,通过提供更加 Swifty 的语法,使得定义模型、访问和查询数据、以及处理数据的插入和删除变得更加容易。
以上是iOS中常用的数据持久化方法,开发者可以根据具体的需求和数据特点选择合适的方法来进行数据持久化操作。
推送
本地推送
远程推送
当服务端远程向APNS推送至一台离线的设备时,苹果服务器Qos组件会自动保留一份最新的通知,等设备上线后,Qos将把推送发送到目标设备上
远程推送的基本过程
- 1.客户端的app需要将用户的UDID和app的bundleID发送给apns服务器,进行注册,apns将加密后的device Token返回给app
- 2.app获得device Token后,上传到公司服务器
- 3.当需要推送通知时,公司服务器会将推送内容和device Token一起发给apns服务器
- 4.apns再将推送内容送到客户端上
创建证书的流程:
- 1.打开钥匙串,生成CertificateSigningRequest.certSigningRequest文件
- 2.将CertificateSigningRequest.certSigningRequest上传进developer,导出.cer文件
- 3.利用CSR导出P12文件
- 4.需要准备下设备token值(无空格)
- 5.使用OpenSSL合成服务器所使用的推送证书
读写锁
读写锁(Read-Write Lock),也称为共享/独占锁(Shared/Exclusive Lock),是一种用于多线程环境中的同步机制,它允许多个线程同时读取共享资源,但在同一时间内只允许一个线程写入。这种锁的设计目的是为了提高并发性能,特别是在读操作远多于写操作的场景中。
读写锁的工作原理如下:
- 读锁(Shared Lock):
- 当一个线程需要读取共享资源时,它会尝试获取读锁。如果当前没有线程持有写锁,那么读锁可以被多个线程同时持有,实现并发读取。
- 读锁是共享的,意味着多个线程可以同时获取读锁并进行读操作。
- 写锁(Exclusive Lock):
- 当一个线程需要写入共享资源时,它会尝试获取写锁。写锁是独占的,即在任何时候只能有一个线程持有写锁。
- 如果有线程已经持有读锁或正在等待写锁,那么新的写锁请求将被阻塞,直到所有读锁被释放,并且没有其他线程持有写锁。
- 锁的升级和降级:
- 在某些情况下,一个线程可能需要从读锁升级到写锁,或者从写锁降级到读锁。这通常涉及到锁的转换机制,需要谨慎处理以避免死锁。
读写锁的优点是在读多写少的场景下,可以显著提高系统的吞吐量,因为它允许多个线程并行地进行读操作,而不是像互斥锁那样在任何时候都只允许一个线程访问资源。
在 iOS 或其他基于 Unix 的系统中,可以通过各种方式实现读写锁,例如使用 POSIX 线程库(Pthreads)中的 pthread_rwlock_* 函数,或者在 Swift 中使用 NSLock、NSRecursiveLock、DispatchSemaphore 等 API。在多线程编程时,选择正确的同步机制对于确保数据一致性和提高性能至关重要。
CI/CD
CI/CD 是现代软件开发中的两个重要概念,代表了持续集成(Continuous Integration)和持续交付/持续部署(Continuous Delivery/Continuous Deployment)。
持续集成(CI)
持续集成是一种软件开发实践,在这种实践中,开发人员频繁地(通常是每天多次)将代码变更合并到共享仓库中。每次代码提交都通过自动化构建进行验证,以尽早发现集成错误、冲突和bug。
CI的主要目标是:
- 减少合并冲突。
- 提供快速反馈。
- 避免“集成地狱”。
- 减少手动测试和发布过程中的错误。
- 提高代码质量。
持续交付(CD)
持续交付是在持续集成的基础上,确保软件可以通过自动化的流程被部署到生产环境。它使得软件的发布变得更加简单和可预测,通常涉及到自动化测试和代码质量检查,以确保代码随时可部署。
持续部署(CD)
持续部署是持续交付的延伸,它指的是代码变更在通过所有生产流水线阶段验证后,自动部署到生产环境。这意味着除了自动化测试外,代码的发布到生产环境也是自动化的。
CI/CD的好处包括:
- 更快的迭代速度和市场响应。
- 更高的软件交付质量。
- 更低的开发和运维成本。
- 更好的客户满意度。
CI/CD是现代DevOps实践和敏捷开发的核心组成部分,通过自动化软件交付过程,帮助团队更快、更频繁地交付高质量的软件产品。在iOS开发中,CI/CD可以通过各种工具实现,如Jenkins、Travis CI、GitLab CI/CD、CircleCI、Fastlane等。这些工具可以帮助自动化构建、测试、打包和部署iOS应用程序,从而提高开发效率和软件质量。
AutoLayout
Auto Layout 是对 UIKit 中的 Auto Layout 功能的封装和简化。Auto Layout 是苹果提供的一种布局方式,用于在 iOS、macOS、watchOS 和 tvOS 应用中创建响应式和灵活的用户界面。其核心思想是通过约束(constraints)来定义视图之间的关系和位置,而不是传统的 frame 或者 bounds 布局方式。
Auto Layout 的主要特点包括:
- 响应式布局:界面可以根据屏幕尺寸、方向变化以及其他布局约束自动调整。
- 灵活性:可以创建复杂的布局,同时保持代码的简洁和可维护性。
- 约束:通过定义视图之间的相对位置、大小和间距等关系,而不是固定的位置和尺寸。
在 Swift 中使用 Auto Layout,通常涉及以下几个步骤:
1. 创建约束(Constraints)
约束定义了视图的属性(如宽、高、顶部、底部、左边距、右边距等)与其他视图或父视图的关系。例如,你可以设置一个视图的左边距等于父视图的左边距加上10点。
1
let constraint = view1.leadingAnchor.constraint(equalTo: view2.leadingAnchor, constant: 10)
2. 激活约束(Activating Constraints)
创建的约束需要被添加到视图中,并激活才能生效。在 iOS 9 及以上版本,可以使用 NSLayoutConstraint.activate 方法来激活约束。
1
NSLayoutConstraint.activate([constraint])
3. 设置优先级(Priority)
某些情况下,可能需要为约束设置优先级,以便在冲突的情况下确定哪些约束应该被满足。约束的优先级是一个介于 UILayoutPriorityRequired(1000)和 UILayoutPriorityDefaultHigh(750)之间的值。
1
constraint.priority = .defaultHigh
4. 使用布局指南(Layout Guides)
布局指南是视图的辅助边缘,可以帮助你更容易地创建符合设计规范的布局。例如,edges 布局指南表示视图的边缘。
1
2
3
4
5
view.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
view.topAnchor.constraint(equalTo: layoutGuide.topAnchor),
view.leadingAnchor.constraint(equalTo: layoutGuide.leadingAnchor)
])
5. 使用链式编程(Chained Programming)
SwiftUI 提供了链式编程的方式来创建和激活约束,使得代码更加简洁。
1
2
3
view.translatesAutoresizingMaskIntoConstraints = false
view.topAnchor.constraint(equalTo: superview.topAnchor).isActive = true
view.leadingAnchor.constraint(equalTo: superview.leadingAnchor).isActive = true
6. 处理安全区域(Safe Area)
在 iPhone X 等带有刘海屏的设备上,需要考虑安全区域,确保内容不会被系统控件遮挡。可以使用 safeAreaLayoutGuide 来创建约束。
1
2
3
4
NSLayoutConstraint.activate([
view.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor),
view.leadingAnchor.constraint(equalTo: view.safeAreaLayoutGuide.leadingAnchor)
])
Auto Layout 是一个强大的工具,它可以帮助你创建出适应不同屏幕尺寸和方向的布局。掌握 Auto Layout 的使用,可以让你的应用在各种设备上都有出色的用户体验。
蓝牙
内购 In-App Purchase
iOS 中的内购(In-App Purchase,简称 IAP)是指在应用程序内部进行的购买行为,允许用户在不离开应用程序的情况下购买虚拟商品或服务。这些虚拟商品可以是游戏内货币、额外关卡、特殊功能解锁、订阅服务等。内购机制是苹果公司为了确保交易安全和公平而提供的一种官方支付方式。
内购的请求流程通常如下:
- 设置内购产品:
- 开发者在 App Store Connect 中设置内购产品,包括产品标识符、定价等信息。
- 用户触发内购:
- 用户在应用程序内选择要购买的虚拟商品,并触发内购流程。
- 请求产品信息:
- 应用程序使用 StoreKit 框架请求内购产品的信息,包括价格、描述等。
- 展示产品信息:
- 开发者将请求到的产品信息展示给用户,以便用户确认购买。
- 用户确认购买:
- 用户确认购买后,应用程序会创建一个内购支付请求。
- 苹果验证请求:
- 苹果服务器验证用户的购买请求,包括用户账户信息和支付授权。
- 扣款并返回购买成功信息:
- 苹果服务器从用户的 Apple ID 账户扣款,并向用户返回购买成功信息。
- 应用程序接收购买信息:
- 应用程序接收到购买成功信息后,解锁相应的虚拟商品或服务。
- 验证收据:
- 为了确保交易的合法性,应用程序需要向苹果的验证服务器发送收据(Receipt),以验证购买的有效性。
- 服务器端验证:
- 如果需要,应用程序可以发送收据到开发者的服务器进行二次验证,确保安全性。
- 发放虚拟商品或服务:
- 验证成功后,应用程序或服务器端会发放相应的虚拟商品或服务给用户。
- 完成交易:
- 交易完成后,应用程序需要通知 StoreKit 完成该笔交易,以便从购买队列中移除。
这个流程确保了内购的安全性和用户的购买体验。开发者需要遵循苹果的内购规则和最佳实践,以避免潜在的问题和应用商店的审核拒绝。
第三方框架
AFNetworking
解析一下AFNetworking实现原理和优缺点?
AFNetworking 是一个用于 iOS、macOS 和 tvOS 的开源网络库, 它建立在Foundation网络层之上,提供了更易用的API和额外的功能,简化了网络请求的创建和处理过程。它基于 Grand Central Dispatch (GCD) 和 OperationQueue 来实现异步网络请求,从而避免了网络操作阻塞主线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
AFNetworking是一个流行的iOS和macOS网络库,用于处理HTTP网络请求。它建立在Foundation网络层之上,提供了更易用的API和额外的功能。以下是对AFNetworking实现原理和优缺点的解析:
实现原理:
1. 封装NSURLConnection:
AFNetworking主要封装了`NSURLConnection`,提供了基于块(Blocks)的回调方式,简化了网络请求的处理。
AFNetworking 提供了多种创建和处理 HTTP 请求的方法。你可以发送 GET、POST、PUT、DELETE 等 HTTP 方法的请求,并且可以添加请求头、设置请求体等。
2. 请求和响应序列化:
支持多种类型的请求和响应序列化,包括 JSON、XML 和 plist 等。这使得处理不同格式的网络响应变得简单。
3. 网络缓存管理:
支持 HTTP 缓存, 提供了对NSURLCache的封装,可以自动缓存请求的响应,以减少不必要的网络请求和提高应用性能。
4. 并发控制:
允许并发执行多个网络请求,并通过GCD(Grand Central Dispatch)进行线程管理。
5. 安全性:
它支持 SSL/TLS 加密,可以配置证书、公钥和私钥,以确保网络传输的安全性。
6. 身份验证:
- 框架提供了对 HTTP 认证的支持,包括基本认证和摘要认证。
7. 可扩展性:
- AFNetworking 设计了一套模块化的架构,允许开发者通过添加子类或类别来扩展其功能。
8. 第三方集成:
AFNetworking 可以与其他库和框架(如 Reachability、OAuth 等)集成,以提供更丰富的功能。
### 优点:
### 缺点:
AFNetworking是一个功能丰富、易于使用的网络库,适用于Objective-C项目。然而,对于Swift项目,可能需要考虑使用更现代的网络库,如Alamofire,它提供了更Swifty的API和更好的语言特性支持。
优缺点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
优点:
1. 简化API:
提供了比原生`NSURLConnection`更简洁易用的API。
2. 强大的功能:
支持多种类型的请求和响应处理,包括上传、下载、缓存等。
3. 易用性:
通过块和分类简化了异步网络请求的处理, 易封装和扩展。
4. 灵活性:
支持自定义请求和响应处理,以及第三方扩展。
缺点:
1. 更新和维护:
随着Apple原生网络API的更新,AFNetworking也需要不断更新以保持兼容性。
2. 性能问题:
在某些情况下,如果不正确使用(如过度创建请求或会话),可能会引起性能问题。
3. 与最新API的兼容性:
随着Swift和iOS的演进,AFNetworking可能在新API的支持上有所滞后。
4. 可能的替代品:
随着Swift和现代网络框架(如Alamofire)的兴起,AFNetworking可能不是所有情况下的最佳选择。
底层原理
- 异步编程模型: AFNetworking 使用 Grand Central Dispatch (GCD) 来处理异步任务。GCD 是苹果提供的一种用于多核编程的解决方案,它允许开发者将任务分配到不同的队列中去执行,从而有效地利用多核处理器的性能。AFNetworking 通过 GCD 将网络请求放到一个单独的队列中,避免了网络请求阻塞主线程,提高了应用的响应速度和用户体验。
- URL加载系统: AFNetworking 基于
NSURLConnection或NSURLSession(取决于 iOS 版本)构建。NSURLConnection是一个用于发送和接收数据的类,而NSURLSession是 iOS 7 引入的新的 URL 加载系统,提供了更丰富的 API 和更好的网络性能。NSURLSession支持后台下载、断点续传等功能,并且可以更好地与 GCD 配合使用。- 请求序列化: AFNetworking 通过序列化请求来管理网络请求的生命周期。序列化器(如
AFHTTPRequestSerializer)负责将请求参数转换为请求体,同时设置合适的 HTTP 方法和请求头。反序列化器(如AFHTTPResponseSerializer)则负责将服务器的响应数据转换为可读的格式(如 JSON、XML)。- 缓存策略: AFNetworking 支持多种缓存策略,包括内存缓存、磁盘缓存和不缓存。它使用
NSURLCache来管理缓存数据,可以自动处理 HTTP 响应头中的缓存指令,如Cache-Control和Expires。- 错误处理和重试机制: AFNetworking 提供了一套错误处理机制,可以捕获网络请求过程中的错误,并根据错误类型决定是否重试请求。它还支持自定义的重试策略,允许开发者根据需要设置重试次数和重试间隔。
- 安全性: 为了确保数据传输的安全性,AFNetworking 支持 SSL/TLS 加密,并允许开发者配置 SSL 证书、公钥和私钥。它还可以处理服务器的 SSL 证书验证和主机名验证,以防止中间人攻击。
- 模块化和扩展性: AFNetworking 的设计允许通过添加子类或类别来扩展其功能。这种模块化的设计使得 AFNetworking 可以很容易地与其他库集成,如 OAuth、Reachability 等。
通过这些底层原理,AFNetworking 能够提供一个强大、灵活且易于使用的网络请求库,帮助开发者在 iOS 和 macOS 应用中处理网络通信。
SDWebImage
SDWebImage是一个流行的iOS和macOS第三方库,用于异步加载和缓存网络图片。它建立在Foundation和UIKit之上,提供了下载、解码、缓存和图像显示的简化API。
SDWebImage 的架构清晰简洁。它由以下几个关键组件组成:
- SDWebImageManager: 负责管理图片加载请求,是访问框架的入口。
- SDImageCache: 负责缓存加载过的图片,优化性能。
- SDWebImageOperation: 异步执行图片加载任务,实现并行加载。
- SDImageTransformer: 可选组件,负责对加载的图片进行变换,如裁剪或缩放。
解析一下SDWebImage实现原理和优缺点?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
异步下载:
SDWebImage使用NSURLSession进行图片的异步下载,不会阻塞主线程。
缓存机制:
支持内存缓存和磁盘缓存。内存缓存使用NSCache来存储图片实例,磁盘缓存使用文件系统存储图片数据。
缓存键管理:
为每个URL生成一个唯一的缓存键,便于缓存管理和查找。
图片解码:
对下载的图片数据进行解码,将其转换为UIImage对象。
占位图:
支持设置一个占位图,在图片下载完成之前显示,提高用户体验。
过渡动画:
提供了一个选项来为图片加载过程添加淡入效果。
内存管理:
通过智能引用计数和内存缓存自动管理,避免内存泄漏。
可扩展性:
允许自定义下载器、缓存器和图片解码器,以适应不同的需求。
图片处理:
支持对下载的图片进行缩放、裁剪等处理。
版本控制:
支持为不同的URL设置不同的版本标识,以便在图片更新时能够重新加载。
优缺点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
优点:
简化的API:
通过链式调用和简洁的API,简化了网络图片加载的过程。
强大的缓存:
内置的缓存机制减少了网络请求,提高了性能。
异步加载:
异步下载图片不会阻塞主线程,提升了应用的响应性。
灵活性和可扩展性:
支持自定义设置和扩展,以适应不同的使用场景。
缺点:
内存消耗:
如果不合理配置内存缓存,可能会消耗大量内存。
磁盘空间:
磁盘缓存可能会占用较多的存储空间,需要合理管理。
可能的性能问题:
如果不正确使用(例如,过度使用内存缓存或磁盘缓存),可能会引起性能问题。
SDWebImage 加载图片的流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
1.入口 setImageWithURL:placeholderImage:options: 会先把 placeholderImage 显示,然后 SDWebImageManager 根据 URL 开始处理图片。
2.进入 SDWebImageManager-downloadWithURL:delegate:options:userInfo:,交给 SDImageCache 从缓存查找图片是否已经下载 queryDiskCacheForKey:delegate:userInfo:.
3.先从内存图片缓存查找是否有图片,如果内存中已经有图片缓存,SDImageCacheDelegate 回调 imageCache:didFindImage:forKey:userInfo: 到 SDWebImageManager。
4.SDWebImageManagerDelegate 回调 webImageManager:didFinishWithImage: 到 UIImageView+WebCache 等前端展示图片。
5.如果内存缓存中没有,生成 NSInvocationOperation 添加到队列开始从硬盘查找图片是否已经缓存。
6.根据 URLKey 在硬盘缓存目录下尝试读取图片文件。这一步是在 NSOperation 进行的操作,所以回主线程进行结果回调 notifyDelegate:。
7.如果上一操作从硬盘读取到了图片,将图片添加到内存缓存中(如果空闲内存过小,会先清空内存缓存)。SDImageCacheDelegate 回调 imageCache:didFindImage:forKey:userInfo:。进而回调展示图片。
8.如果从硬盘缓存目录读取不到图片,说明所有缓存都不存在该图片,需要下载图片,回调 imageCache:didNotFindImageForKey:userInfo:。
9.共享或重新生成一个下载器 SDWebImageDownloader 开始下载图片。
10.图片下载由 NSURLConnection 来做,实现相关 delegate 来判断图片下载中、下载完成和下载失败。
11.connection:didReceiveData: 中利用 ImageIO 做了按图片下载进度加载效果。
12.connectionDidFinishLoading: 数据下载完成后交给 SDWebImageDecoder 做图片解码处理。
13.图片解码处理在一个 NSOperationQueue 完成,不会拖慢主线程 UI。如果有需要对下载的图片进行二次处理,最好也在这里完成,效率会好很多。
14.在主线程 notifyDelegateOnMainThreadWithInfo: 宣告解码完成,imageDecoder:didFinishDecodingImage:userInfo: 回调给 SDWebImageDownloader。
15.imageDownloader:didFinishWithImage: 回调给 SDWebImageManager 告知图片下载完成。
16.通知所有的 downloadDelegates 下载完成,回调给需要的地方展示图片。
17.将图片保存到 SDImageCache 中,内存缓存和硬盘缓存同时保存。写文件到硬盘也在以单独 NSInvocationOperation 完成,避免拖慢主线程。
18.SDImageCache 在初始化的时候会注册一些消息通知,在内存警告或退到后台的时候清理内存图片缓存,应用结束的时候清理过期图片。
19.SDWI 也提供了 UIButton+WebCache 和 MKAnnotationView+WebCache,方便使用。
20.SDWebImagePrefetcher 可以预先下载图片,方便后续使用。
1、SDImageCache是怎么做数据管理的?
SDImageCache分两个部分,一个是内存层面的,一个是硬盘层面的。内存层面的相当是个缓存器,以Key-Value的形式存储图片。当内存不够的时候会清除所有缓存图片。用搜索文件系统的方式做管理,文件替换方式是以时间为单位,剔除时间大于一周的图片文件。当SDWebImageManager向SDImageCache要资源时,先搜索内存层面的数据,如果有直接返回,没有的话去访问磁盘,将图片从磁盘读取出来,然后做Decoder,将图片对象放到内存层面做备份,再返回调用层。
2、为啥必须做Decoder?
由于UIImage的imageWithData函数是每次画图的时候才将Data解压成ARGB的图像,所以在每次画图的时候,会有一个解压操作,这样效率很低,但是只有瞬时的内存需求。为了提高效率通过SDWebImageDecoder将包装在Data下的资源解压,然后画在另外一张图片上,这样这张新图片就不再需要重复解压了。
RxSwift
Combine
IGListKit
Texture
Moya
SwiftLint
SwiftLint是一个用于Swift代码的静态分析工具,它帮助开发者遵守代码规范、最佳实践和样式指南。SwiftLint可以自动检测潜在的错误、代码风格问题和一些常见的陷阱。以下是对SwiftLint实现原理的解析:
解析一下SwiftLint实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1. 抽象语法树(AST, Abstract Syntax Tree)
SwiftLint利用Swift编译器生成的AST来分析代码结构。AST是源代码的树状表示,其中节点表示代码中的结构元素,如类、函数、变量等。
2. 规则引擎
SwiftLint包含一套可配置的规则引擎,用于定义代码应该遵循的规范。这些规则可以是警告、错误或可以自动修复的。
3. 规则触发
当分析代码时,SwiftLint会遍历AST中的每个节点,并检查它们是否触发了任何规则。如果代码结构与规则定义的条件匹配,就会生成相应的警告或错误。
4. 自动修正
许多SwiftLint规则不仅能够检测问题,还能提供自动修正的解决方案。开发者可以选择应用这些自动修正来快速改进代码质量。
5. 配置文件
SwiftLint的配置可以通过`.swiftlint.yml`文件进行,开发者可以定义启用哪些规则、规则的严重性级别以及自定义规则参数。
6. 命令行界面(CLI)
SwiftLint提供一个命令行界面,允许开发者从终端运行代码检查、应用自动修正和生成报告。
7. 集成开发环境(IDE)集成
SwiftLint可以集成到Xcode和其他IDE中,提供实时的代码质量反馈。
8. 可扩展性
SwiftLint允许开发者编写自定义规则,以适应特定的编码需求或风格指南。
9. Swift编译器交互
SwiftLint与Swift编译器交互,利用编译器的AST生成功能来获取代码的准确表示。
10. 性能优化
SwiftLint进行了性能优化,以确保即使在大型项目上也能快速运行。
优缺点
1
2
3
4
5
6
7
8
9
10
优点:
自动化:自动化代码审查,减少人为错误。
一致性:帮助团队保持代码风格的一致性。
可配置性:规则可配置,适应不同团队的需求。
实时反馈:集成到IDE,提供实时的代码质量反馈。
缺点:
学习曲线:需要时间来学习如何配置和使用SwiftLint。
性能影响:在非常大的项目上可能影响构建速度。
规则限制:虽然可扩展,但自定义规则可能需要一定的开发工作。
URLNavigator
URLNavigator是一个用于处理iOS应用中导航的路由库,它提供了一种声明式的方式来定义和执行导航逻辑。以下是对URLNavigator实现原理的解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
1.URL路由表
URLNavigator使用一个路由表来映射URL模式和对应的处理逻辑。这个路由表是导航系统的核心,用于匹配传入的URL并找到相应的处理器。
2. URL模式
每个路由都有一个对应的URL模式,通常是一个字符串,它定义了URL的结构和可能的参数。模式可以使用参数占位符来匹配不同的值。
3. 处理器(Handlers)
处理器是导航逻辑的具体实现,它们定义了如何处理匹配到的URL。处理器可以是一个闭包或一个实现了特定协议的对象。
4. 导航请求
导航请求是一个包含URL和可能的参数的对象。当发起导航请求时,URLNavigator会使用路由表来解析这个请求。
5. 匹配和解析
当收到一个导航请求,URLNavigator会遍历路由表,尝试找到匹配的URL模式。如果找到匹配项,它会使用相应的处理器来执行导航。
6. 参数解析
URLNavigator支持从URL中解析参数,并将它们传递给处理器。这允许导航逻辑根据URL中的参数动态变化。
7. 导航执行
一旦匹配到处理器,URLNavigator会执行它,通常涉及到实例化视图控制器、设置属性、导航到新页面等操作。
8. 可配置性
URLNavigator提供了灵活的配置选项,允许开发者自定义路由表、处理器的行为,甚至自定义URL的匹配和解析逻辑。
9. 链式导航
URLNavigator支持链式导航,即一个导航请求的处理结果可以触发另一个导航请求。
10. 集成性
URLNavigator可以轻松集成到现有的iOS项目中,与UIKit或 SwiftUI等框架协同工作。
URLNavigator是一个强大的导航库,适用于需要复杂导航逻辑的iOS应用。通过将导航逻辑与视图控制器分离,它提高了代码的可维护性和可扩展性。然而,开发者应该根据项目的具体需求来决定是否引入这个库。
Realm
Realm是一个流行的移动数据库解决方案,用于在iOS、Android、React Native以及许多其他平台上提供高性能的对象存储。Swift Realm库是为Swift语言定制的API,提供了对Realm数据库的访问和操作。以下是对Swift Realm库实现原理的解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1. 线程安全
- Realm数据库是线程安全的,这意味着它可以在不同的线程上并发访问。Swift Realm库封装了这些线程安全的细节,使得开发者可以安全地在后台线程上执行数据库操作。
2. 持久化存储
- Realm数据库将数据存储在本地文件系统中,Swift Realm库提供了API来管理这些文件,包括创建、打开和迁移数据库。
3. 对象映射
- 使用Swift Realm库,开发者可以定义模型类或结构体,这些类或结构体的属性将映射到数据库中的列。Realm通过反射机制来识别这些属性,并在后台生成相应的数据库模式。
4. 数据访问和查询
- Swift Realm库提供了丰富的API来查询和管理数据。包括基本的增删改查操作,以及更复杂的查询,如排序、过滤和聚合。
5. 原生支持
- Realm为Swift语言提供了原生的支持,包括对泛型、协议以及Swift特有的类型系统的支持。
6. 写入事务
- Realm支持在事务中进行写入操作,确保数据的一致性和完整性。Swift Realm库提供了简化的API来开始、提交或回滚事务。
7. 监听和通知
- Realm可以监听数据变化,并在数据发生变化时发送通知。Swift Realm库允许开发者注册监听器,以响应这些变化。
8. 迁移支持
- 当模型发生变化时,Realm支持数据库模式的迁移。Swift Realm库提供了迁移API,使得在应用更新时可以平滑过渡到新的数据库模式。
9. 集成和扩展性
- Realm可以与其他框架和库集成,如使用Swift的Combine框架进行数据流的响应式编程。
10. 跨平台
- Realm是一个跨平台的数据库,Swift Realm库使得在iOS上使用Realm变得容易,但Realm的数据可以跨多个平台共享。
优点:
性能:Realm以其高性能读写操作而闻名,特别是在移动设备上。
易用性:Swift Realm库提供了简单直观的API,使得在Swift中使用Realm变得容易。
实时更新:Realm可以实时监听数据变化并通知更新,适合需要实时数据同步的应用。
缺点:
学习成本:对于初学者,理解Realm的工作原理和最佳实践可能需要一些时间。
平台限制:虽然Realm是跨平台的,但某些特定平台的特性可能不完全相同。
依赖管理:作为第三方库,Realm需要依赖管理,这可能会带来版本兼容性问题。
Swift Realm库为Swift开发者提供了一个强大且易于使用的本地数据库解决方案,尤其适合需要高性能和实时数据同步的场景。然而,开发者应该根据项目需求和团队熟悉度来决定是否使用Realm。
SnapKit
Swift总结
0.谈一下Objective-c和Swift,有什么区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
Objective-C和Swift都是苹果公司用于iOS、macOS、watchOS和tvOS应用开发的编程语言,但它们在设计理念、语法和特性上存在显著差异:
语言起源和历史:
Objective-C: 起源于20世纪80年代,是一种面向对象的编程语言,基于C语言,并加入了面向对象的特性。
Swift: 于2014年由苹果发布,是一种现代的、安全的、高性能的编程语言,设计时考虑了易用性和与Cocoa框架的互操作性。
语法和可读性:
Objective-C: 语法较为复杂,使用基于C的语法,并加入了消息传递机制来实现面向对象的特性。
Swift: 提供了更简洁、易读的语法,减少了样板代码,使得Swift代码更易于编写和理解。
内存管理:
Objective-C: 使用手动引用计数(MRC)或自动引用计数(ARC)来管理内存,开发者需要手动或自动管理对象的内存释放。
Swift: 采用ARC机制,简化了内存管理,减少了内存泄漏和其他内存相关问题的风险。
类型安全:
Objective-C: 是一种动态类型语言,类型检查主要在运行时进行,这可能导致运行时错误。
Swift: 是一种静态类型语言,提供了更严格的类型检查,有助于在编译时捕捉错误。
错误处理:
Objective-C: 通常使用NSError或抛出异常的方式处理错误。
Swift: 引入了错误处理机制,使用do-catch-throw语句和自定义错误类型来处理错误。
泛型:
Objective-C: 不支持泛型编程。
Swift: 支持泛型,允许开发者编写类型安全的、可重用的代码。
性能:
Objective-C: 由于其底层基于C语言,通常具有很高的性能。
Swift: 也被设计为高性能的语言,并且在某些情况下,由于其优化的内存管理和现代编译器技术,可能比Objective-C更快。
与Cocoa和Objective-C的互操作性:
Swift可以无缝桥接Objective-C代码,允许开发者在Swift项目中使用Objective-C的库和框架。
社区和生态系统:
Objective-C拥有一个成熟的开发者社区和大量的库,但由于Swift的推出,新的库和框架越来越多地使用Swift。
Swift拥有一个快速增长的开发者社区,并且得到了苹果的大力支持,拥有丰富的学习资源和框架。
1.介绍一下 Swift?
Swift是苹果在2014年6月WWDC发布的全新编程语言,借鉴了JS,Python,C#,Ruby等语言特性,看上去偏脚本化,Swift 仍支持 cocoa touch 框架
1
2
3
4
5
6
优点:
Swift更加安全,它是类型安全的语言。
Swift容易阅读,语法和文件结构简易化。
Swift更易于维护,文件分离后结构更清晰。
Swift代码更少,简洁的语法,可以省去大量冗余代码
Swift速度更快,运算性能更高。
解析一下SwiftUI
SwiftUI 是苹果公司开发的一种用于构建用户界面的现代框架,它允许开发者使用 Swift 语言来创建 iOS、macOS、watchOS 和 tvOS 应用程序的界面。SwiftUI 以其声明式语法而著称,使得开发者可以更加直观和简洁地编写界面代码。
以下是一些关于 SwiftUI 的关键点:
声明式语法:SwiftUI 允许开发者通过声明界面的最终状态来构建应用,而不是通过命令式编程来逐步构建和修改界面。
响应式编程:SwiftUI 支持响应式编程,这意味着当数据变化时,界面会自动更新以反映这些变化。
跨平台:虽然 SwiftUI 最初是为 iOS 设计的,但它也被扩展到了 macOS、watchOS 和 tvOS,允许开发者使用相同的代码库来创建跨平台的应用程序。
预览功能:SwiftUI 允许开发者在编写代码时实时预览界面,这大大提高了开发效率。
数据绑定:SwiftUI 支持数据绑定,使得开发者可以轻松地将模型数据与界面控件连接起来。
动画和过渡效果:SwiftUI 提供了丰富的动画和过渡效果,使得开发者可以创建流畅和吸引人的用户体验。
模块化和可重用性:SwiftUI 鼓励模块化设计,开发者可以创建可重用的视图组件,简化代码并提高代码的可维护性。
性能优化:SwiftUI 旨在提供高性能的界面渲染,减少应用程序的内存占用和提高响应速度。
集成开发环境 (IDE) 支持:SwiftUI 与 Xcode 紧密集成,提供了丰富的工具和功能来辅助开发。
社区和资源:由于 SwiftUI 是苹果公司的产品,它拥有庞大的开发者社区和丰富的学习资源。
SwiftUI 作为一种新兴的 UI 框架,正在逐渐成为苹果平台上的首选界面开发工具。随着苹果对 SwiftUI 的不断更新和改进,它的功能和性能也在不断提升。
2.Swift 和OC 如何相互调用?
Swift 调用 OC代码
- 需要创建一个 Target-BriBridging-Header.h 的桥文件,在乔文件导入需要调用的OC代码头文件即可
OC 调用 Swift代码
- 直接导入 Target-Swift.h文件即可, Swift如果需要被OC调用,需要使用@objc 对方法或者属性进行修饰
4.Swift中什么是泛型?
- 泛型主要是为增加代码的灵活性而生的,它可以是对应的代码满足任意类型的的变量或方法;
- 泛型可以将类型参数化,提高代码复用率,减少代码量
1
2
3
4
// 实现一个方法,可以交换任意类型
func swap<T>(a: inout T, b: inout T) {
(a, b) = (b, a)
}
5.Swift 访问控制关键字的区别?
Swift 中有个5个级别的访问控制权限,从高到低依次是 open, public, internal, fileprivate, private 它们遵循的基本规则: 高级别的变量不允许被定义为低级别变量的成员变量.
open: 具备最高访问权限, 其修饰的类可以在任意模块中被访问和重写public: 权限仅次于 open, 和 open 唯一的区别是: 不允许其他模块进行继承、重写internal: 默认权限, 只允许在当前的模块中访问,可以继承和重写, 不允许在其他模块中访问fileprivate: 修饰的对象只允许在当前的文件中访问private: 最低级别访问权限, 只允许在定义的作用域内访问
6.Swift关键字Strong,Weak,Unowned 区别?
在Swift中,strong、weak和unowned是用于定义属性或变量时的所有权修饰符,它们主要用于类(Class)之间的引用。这些修饰符帮助管理内存,特别是在自动引用计数(ARC)环境中,以避免循环引用等问题。以下是它们的主要区别:
- Strong:
strong是默认的所有权修饰符。- 创建一个强引用,意味着被引用的实例的引用计数会增加。
- 如果两个类互相强引用,将导致循环引用,因为它们的引用计数永远不会降到零。
- 强引用通常用于大多数情况,除非需要避免循环引用。
- Weak:
weak修饰符用于创建一个弱引用,不会引起引用计数的增加。- 弱引用在引用的对象被释放时,会自动置为
nil。 - 弱引用通常用于避免循环引用,特别是在代理模式或闭包中。
weak变量总是可选的,因为它可能在任何时候变为nil。
- Unowned:
unowned修饰符用于创建一个无主引用,也不增加引用计数。- 与
weak不同,unowned引用假定它引用的对象在引用的整个生命周期内始终存在。如果被引用的对象先于unowned引用被释放,将会导致运行时崩溃。 unowned通常用于单向关系,即你知道被引用的对象的生命周期至少和引用它的对象一样长。unowned变量不是可选的,因为它假定总是有一个有效的引用。
注意事项:
- 使用
weak和unowned修饰符时,需要小心管理生命周期,以避免潜在的崩溃。 - 由于
weak和unowned变量可能会引用nil,在使用它们之前通常需要进行空值检查。 unowned特别适用于你知道引用的对象不会被销毁,或者在对象可能被销毁之前不再需要引用的场景。
7.Swift中存储属性和计算属性的区别?
在Swift中,属性可以分为两大类:存储属性(Stored Properties)和计算属性(Computed Properties)。它们之间的主要区别如下:
- 存储属性:
- 存储属性实际上存储了一个值在内存中。
- 它们可以是变量(使用
var关键字),也可以是常量(使用let关键字)。 - 存储属性可以直接被赋值和读取。
- 结构体、类可以定义存储属性,枚举不可以定义存储属性。
- 计算属性:
- 计算属性不存储值,而是提供一个getter和(可选的)setter来间接获取和设置其他属性或值
- 它们类似于存储属性,但它们的值不是直接存储的,而是通过执行计算得到的
- 计算属性使用
var关键字定义,并且没有明确的存储类型 - 枚举、结构体、类都可以定义计算属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 存储属性
struct Rectangle {
var width: Double
var height: Double
}
// 计算属性
class Person {
var firstName: String = "John"
var lastName: String = "Doe"
var fullName: String { // 计算属性
get {
return "\(firstName) \(lastName)"
}
set {
let names = newValue.split(separator: " ")
firstName = names.first ?? ""
lastName = names.last ?? ""
}
}
}
8.Swift什么是属性观察?
在Swift中,属性观察(Property Observers)是一种机制,允许你在属性值发生变化时执行代码。属性观察可以应用于存储属性(stored properties),包括类(class)和结构体(struct)的属性。Swift提供了以下几种属性观察器:
willSet: 在属性的值将要被设置之前调用。didSet: 在属性的值被设置之后调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Person {
var name: String {
willSet(newName) {
print("即将将名字从 \(name) 改为 \(newName)")
}
didSet {
if name != oldValue {
print("名字已从 \(oldValue) 改为 \(name)")
}
}
}
init(name: String) {
self.name = name
}
}
特点:
- 属性观察器只会观察存储属性的值,不会观察计算属性(computed properties)的值。
willSet和didSet观察器不能用于let常量的属性,因为常量的值一旦初始化后就不能改变。- 在
didSet观察器中,如果属性的值没有实际改变(即新旧值相同),观察器代码块将不会被执行。 - 属性观察器可以用于调试、验证、记录日志等场景,也可以用于自动更新其他属性或执行其他相关操作。
9.Swift 为什么将 String,Array,Dictionary设计为值类型?
值类型和引用类型相比,最大优势可以高效的使用内存。值类型在栈上操作,引用类型在堆上操作栈上操作,仅仅是单个指针的移动,而堆上操作牵涉到合并、位移、重链接。Swift 这样设计减少了堆上内存分配和回收次数,使用 copy-on-write将值传递与复制开销降到最低。
10.如何将Swift 中的协议(protocol)中的部分方法设计为可选(optional)?
- 1.在协议和方法前面添加 @objc,在方法前面添加 optional关键字
- 2.使用扩展
extension,来规定可选方法。在 swift 中协议扩展可以定义部分方法的默认实现
1
2
3
4
5
6
7
8
9
10
@objc protocol SomeProtocol: AnyObject {
@objc optional func text()
}
// 或者
protocol SomeProtocol: AnyObject {
func text()
}
extension SomeProtocol {
func test() {}
}
11.Swift 和Objective-C中的初始化方法 (init) 有什么不同?
Swift和Objective-C是两种不同的编程语言,它们在语法和初始化方法上有一些显著的差异。以下是Swift和Objective-C初始化方法的一些主要区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
1.语法:
Swift: 使用简洁的语法定义初始化方法,并且可以为类提供多个初始化方法。
class MyClass {
var property: String
init(property: String) {
self.property = property
}
}
Objective-C: 使用- (instancetype)init方法定义初始化方法,通常使用self来指代当前对象。
@interface MyClass : NSObject
@property (nonatomic, strong) NSString *property;
@end
@implementation MyClass
- (instancetype)init {
self = [super init];
if (self) {
_property = nil;
}
return self;
}
@end
2.继承:
Swift: 子类必须调用super.init来确保类的层级结构中的每个父类都被正确初始化。
Objective-C: 类似于Swift,子类必须调用[super init]来初始化父类。
3.可失败初始化:
Swift: 可以定义一个可失败的初始化方法(init?),如果初始化失败,可以返回nil。
Objective-C: 没有原生的可失败初始化概念,但可以通过返回nil来模拟。
4.构造器的重载:
Swift: 可以为类定义多个构造器,Swift会自动处理构造器的重载。
Objective-C: 也可以定义多个初始化方法,但需要确保每个方法都有不同的参数签名。
5.内存管理:
Swift: 使用自动引用计数(ARC)来管理内存,初始化方法不需要手动管理内存。
Objective-C: 需要手动管理内存,例如在初始化方法中使用retain、release或autorelease。
6.默认初始化方法:
Swift: 如果没有定义任何初始化方法,Swift会提供一个无参数的默认初始化方法。
Objective-C: 需要至少提供一个初始化方法,通常是init。
7.便利初始化方法(Convenience Initializer):
Swift: 可以使用convenience关键字定义便利初始化方法,这些方法通常调用同一个类中的其他初始化方法。
Objective-C: 没有convenience关键字,但可以通过调用其他初始化方法来实现类似的功能。
8.初始化完成后的操作:
Swift: 初始化完成后,可以使用属性观察器(如willSet和didSet)来执行额外的操作。
Objective-C: 通常在init方法的最后设置属性的初始值。
12.Swift和Objective-C中的 protocol 有什么不同?
Swift和Objective-C都支持协议(Protocol)的概念,但它们在语法和功能上有一些不同。以下是Swift和Objective-C中协议的主要区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
1.语法:
Swift: 使用protocol关键字定义协议,可以包含方法、属性、构造器、关联类型(associated types)等。
protocol MyProtocol {
var mustBeSet: Int { get set }
func requiredMethod()
}
Objective-C: 使用@protocol关键字定义协议,通常包含方法的声明。
@protocol MyProtocol
- (void)requiredMethod;
@end
2.扩展性:
Swift: 协议可以被扩展,这意味着你可以向协议添加默认实现,使得遵循协议的类型可以继承这些实现。
Objective-C: 协议不能被扩展,它们仅定义了一个需要实现的接口。
3.类型约束:
Swift: 协议可以用于类、结构体、枚举等,并且可以与泛型结合使用。
Objective-C: 协议主要用于类,并且不支持与泛型的结合。
4.协议继承:
Swift: 协议可以继承其他协议,形成协议的层级结构。
Objective-C: 协议也可以继承其他协议,但语法上使用逗号分隔多个继承的协议。
5.协议作为类型:
Swift: 协议本身可以作为类型使用,例如作为函数参数或返回类型。
Objective-C: 协议通常不直接作为类型使用,而是作为对象的类型约束。
6.可选协议方法:
Swift: 协议中可以定义可选方法(optional methods),遵循协议的类型可以选择实现这些方法。
Objective-C: 没有原生的可选方法概念,但可以通过提供默认实现或使用特定的方法名来模拟。
7.协议合成:
Swift: 不支持协议合成(protocol composition),但可以使用协议继承来达到类似效果。
Objective-C: 支持使用加号(+)来合成多个协议,形成一个新的协议。
8.协议属性:
Swift: 协议可以要求实现特定的属性,这些属性可以是存储属性或计算属性。
Objective-C: 协议通常不用于定义属性,而是定义方法。
9.协议的默认实现:
Swift: 可以在协议扩展中为协议方法提供默认实现,遵循协议的类型可以调用这些默认实现。
Objective-C: 不支持在协议中提供默认实现,必须由遵循协议的类型提供具体实现。
13. protocol 和 category 中如何使用 property
1
2
3
4
1)在protocol中使用property只会生成setter和getter方法声明,我们使用属性的目的,是希望遵守我协议的对象能实现该属性.
2)category 使用 @property 也是只会生成setter和getter方法的声明,如果我们真的需要给category增加属性的实现,需要借助于运行时的两个函数:
①objc_setAssociatedObject
②objc_getAssociatedObject
14.什么是函数重载? swift 支不支持函数重载?
在Swift中,函数重载(Function Overloading)是一种让同一个函数名具有多个实现的能力,这些实现在参数的类型、数量或顺序上有所不同。这允许你定义多个函数,它们具有相同的名称,但接受不同数量或类型的参数。
函数重载的特点:
- 参数列表不同:可以通过改变参数的数量或类型来重载函数。
- 参数标签不同:即使参数列表相同,改变参数的外部名称(标签)也可以实现函数重载。
- 默认参数值:为函数参数提供默认值,可以在调用时省略这些参数,从而实现一种形式的重载。
- 可变参数:使用可变参数(接受零个或多个值的参数)也可以实现重载的效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
func printMessage(_ message: String) {
print("Message: \(message)")
}
// 参数类型不同
func printMessage(_ message: Int) {
print("Message: \(message)")
}
// 参数标签不同
func printMessage(_ message: String, from sender: String) {
print("Message from \(sender): \(message)")
}
注意事项:
- 函数重载在Swift中是类型安全的,编译器会根据传递的参数类型或数量来确定调用哪个函数。
- 函数重载是编译时特性,意味着重载的决策是在编译期间做出的,而不是在运行时。
- 函数重载可以提高代码的可读性和可用性,但过度使用可能导致代码复杂度增加。
15.Swift 中枚举的关联值和原始值的区分?
在Swift中,枚举(Enumerations,简称Enums)是一种特殊的类型,可以包含定义的一组相关的值。Swift的枚举非常灵活,支持两种特殊的功能:关联值(Associated Values)和原始值(Raw Values)。
枚举的原始值(Raw Values):
- 枚举的原始值是枚举成员的默认值,每个枚举成员可以指定一个原始值。
- 原始值可以是数字(如
Int、Float等)、字符串String或任何其他类型的值。 - 当枚举定义了原始值类型时,枚举成员必须提供该类型的值。
1
2
3
enum Fruit {
case apple, banana, orange
}
枚举的关联值(Associated Values):
- 关联值允许枚举的成员携带额外的数据,这些数据可以是任何类型。
- 每个枚举成员可以定义不同的关联值类型,这使得枚举非常灵活。
- 通过关联值,枚举成员可以携带不同数量和类型的数据。
1
2
3
4
5
enum PaymentMethod {
case creditCard(number: String, expirationDate: String)
case paypal(email: String)
case cash(amount: Double)
}
16.Swift 中的闭包结构是什么样子的?
在Swift中,闭包(Closures)是一种自包含的函数代码块,可以被保存并到处传递。Swift的闭包语法结构包括以下几个部分:
- 参数列表:与函数一样,闭包可以接受零个或多个参数。参数定义在花括号
{}之前,参数列表格式为(parameters: types)。 - 返回类型:如果闭包的返回类型不是
Void,需要指定返回类型,放在参数列表之后,用箭头->分隔。 - 捕获列表:闭包可以捕获并存储对外部常量和变量的引用,捕获列表在参数列表之前,使用
[捕获列表]来定义。 - 函数体:闭包的代码实现部分,使用花括号
{}包围。 - 返回语句:如果闭包有返回值,需要在函数体中使用
return语句返回值。
1
2
3
4
5
6
7
8
9
10
11
12
// 示例
{ (parameters: types) -> returnType in
// 闭包体
}
// 一个简单的闭包,无参数,返回`Void`
let simpleClosure: () -> Void = {
print("Hello, World!")
}
// 一个带参数的闭包,返回`Int`
let additionClosure = { (a: Int, b: Int) -> Int in
return a + b
}
17.Swift中什么是尾随闭包?
在Swift中,尾随闭包(Trailing Closure)是一种特殊的闭包语法,用于在函数调用中简化闭包的书写。当一个函数的最后一个参数是一个闭包时,你可以将这个闭包写在函数调用的圆括号之外,称之为尾随闭包。这样做的好处是提高了代码的可读性,尤其是在闭包较长或者参数较多的情况下。
尾随闭包的使用条件:
- 闭包是函数的最后一个参数:只有当闭包是函数参数列表中的最后一个参数时,才可以使用尾随闭包。
- 参数标识:如果函数的其他参数也有默认值或者可以通过上下文推断,尾随闭包可以省略参数名称。
1
2
3
4
5
6
7
8
9
// 假设有一个接受两个参数的函数,第二个参数是一个闭包
func performOperation(on value: Int, then closure: (Int) -> Int) {
let result = closure(value)
print(result)
}
// 使用尾随闭包调用函数
performOperation(on: 5) { $0 * 3 }
// 等同于
performOperation(on: 5, then: { $0 * 3 })
尾随闭包的优点:
- 提高可读性:长闭包从函数调用中分离出来,使函数调用更加清晰。
- 减少括号:不需要在闭包前加额外的圆括号。
- 简化书写:特别是在闭包较短时,可以省略参数名称和花括号。
注意事项:
- 当闭包是函数的最后一个参数,并且它的类型可以被推断出来时,可以省略花括号和参数名称。
- 如果函数有多个参数,尾随闭包必须使用圆括号包围。
18.Swift中什么是逃逸闭包?
在Swift中,逃逸闭包(Escaping Closure)是一种定义在函数或方法外部,但会在函数或方法返回之后才被调用的闭包。这意味着闭包需要在函数的作用域之外保持存在,因此编译器需要为逃逸闭包分配堆内存(而不是栈内存),以保证它们在函数返回后仍然可以被访问和执行。
逃逸闭包的特点:
- 延迟执行:逃逸闭包在定义它的函数返回后执行,可能在另一个线程或在不确定的时间点。
- 存储位置:由于可能在函数返回后执行,逃逸闭包通常存储在堆上,而不是栈上。
- 强引用捕获:如果逃逸闭包捕获了对外部变量的强引用,需要使用
[weak self]或[unowned self]来避免循环引用和内存泄漏。
逃逸闭包的使用场景:
- 当你使用异步API,如定时器、动画、延迟执行、回调、事件处理等,闭包可能作为回调在异步操作完成后执行。
- 当闭包作为参数传递给函数,并且该函数在返回之前没有调用这个闭包,闭包将逃逸。
1
2
3
4
5
6
7
8
9
10
11
12
13
var completionHandlers: [() -> Void] = []
func executeAfterDelay(_ delay: TimeInterval, closure: @escaping () -> Void) {
completionHandlers.append(closure)
// 模拟异步操作
DispatchQueue.main.asyncAfter(deadline: .now() + delay) {
self.completionHandlers.forEach { $0() }
}
}
// 使用逃逸闭包
executeAfterDelay(2) {
print("This message is printed after 2 seconds")
}
注意事项:
- 当使用
@escaping关键字时,编译器会要求你为闭包捕获的任何弱或无主引用添加[weak]或[unowned]修饰符。 - 如果闭包不是逃逸的,不需要使用
@escaping,并且可以使用更简单的[]捕获列表。 - 逃逸闭包可能导致内存管理问题,因此需要小心使用,特别是在捕获外部变量时。
19.简要说明Swift中的初始化器?
- 类、结构体、枚举都可以定义初始化器
- 类有2种初始化器: 指定初始化器(designated initializer)、便捷初始化器(convenience initializer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Car {
var model: String
var year: Int
// 指定初始化器
init(model: String, year: Int) {
self.model = model
self.year = year
}
// 便利初始化器
convenience init() {
self.init(model: "Unknown", year: 0)
}
}
let car = Car(model: "Tesla", year: 2021)
let defaultCar = Car() // 使用便利初始化器
20.Swift中什么是运算符重载(Operator Overload)?
运算符重载(Operator Overloading)是一种特性,它允许开发者为自定义类型定义或修改大多数运算符(如+、-、*、/等)的行为。通过运算符重贷,你可以定义如何使用标准运算符来操作你的类的实例或结构体的实例。
运算符重载的目的:
- 一致性:使得自定义类型与内置类型在使用上具有一致性。
- 可读性:提高代码的可读性,使操作自定义类型的代码更自然和直观。
- 灵活性:为自定义类型提供与内置类型相似的操作方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
struct Vector2D {
var x: Double
var y: Double
}
// 重载加法运算符
static func + (left: Vector2D, right: Vector2D) -> Vector2D {
return Vector2D(x: left.x + right.x, y: left.y + right.y)
}
// 重载点乘运算符
static func • (left: Vector2D, right: Vector2D) -> Double {
return left.x * right.x + left.y * right.y
}
运算符重载的规则:
- 你可以重载大多数二元运算符(如
+、-等)和一些一元运算符(如++、--、!等)。 - 你不能重载赋值运算符
=、成员访问运算符.、下标访问运算符[]等。 - 运算符重载的方法必须是静态的(
static)或类的(class)。 - 运算符重载的方法应该明确指定其操作数的类型。
注意事项:
- 运算符重载应该保持其原有的语义,避免改变运算符的传统含义。
- 运算符重载应该保持一致性,例如,如果你重载了
+,可能还需要重载-。 - 运算符重载可以提高代码的可读性,但滥用可能导致代码难以理解和维护。
21.Swift中什么可选链?
可选链(Optional Chaining)是一种安全快捷的方法,用于处理可能为nil的可选类型(Optionals)。可选链允许你访问可选类型的属性、方法或下标,而不必显式地检查nil值。如果可选类型包含值,可选链将自动取消包装(unwrap)并访问其值;如果为nil,则整个可选链表达式的结果为nil,并且不会进一步执行链式调用。
可选链的特点:
- 安全性:使用可选链可以避免在访问可选类型的值时发生运行时崩溃。
- 简洁性:可选链减少了编写
if let或guard let语句的需要,使代码更简洁。 - 表达性:可选链使得意图清晰,即你想要访问一个可能不存在的值。
1
2
3
4
5
6
7
8
class Person {
var residence: Residence?
}
class Residence {
var address: String?
}
let person: Person? = Person()
let address = person?.residence?.address // 使用可选链访问嵌套的可选值
22.深浅复制和属性为copy,strong值的变化问题
1
2
3
4
5
6
7
浅复制:只复制指向对象的指针,而不复制引用对象本身。对于浅复制来说,A和A_copy指向的是同一个内存资源,复制的只不个是一个指针,对象本身资源还是只有一份,那如果我们对A_copy执行了修改操作,那么发现A引用的对象同样被修改了。深复制就好理解了,内存中存在了两份独立对象本身。
在Objective-C中并不是所有的对象都支持Copy,MutableCopy,遵守NSCopying协议的类才可以发送Copy消息,遵守NSMutableCopying协议的类才可以发送MutableCopy消息。
[immutableObject copy] // 浅拷贝
[immutableObject mutableCopy] //深拷贝
[mutableObject copy] //深拷贝
[mutableObject mutableCopy] //深拷贝
23.NSTimer创建后,会在哪个线程运行
1
2
用scheduledTimerWithTimeInterval创建的,在哪个线程创建就会被加入哪个线程的RunLoop中就运行在哪个线程。
自己创建的Timer,加入到哪个线程的RunLoop中就运行在哪个线程。
24.KVO,NSNotification,delegate及block区别
1
2
3
4
5
6
7
KVO就是cocoa框架实现的观察者模式,一般同KVC搭配使用,通过KVO可以监测一个值的变化,比如View的高度变化。是一对多的关系,一个值的变化会通知所有的观察者。
NSNotification是通知,也是一对多的使用场景。在某些情况下,KVO和NSNotification是一样的,都是状态变化之后告知对方。NSNotification的特点,就是需要被观察者先主动发出通知,然后观察者注册监听后再来进行响应,比KVO多了发送通知的一步,但是其优点是监听不局限于属性的变化,还可以对多种多样的状态变化进行监听,监听范围广,使用也更灵活。
delegate 是代理,就是我不想做的事情交给别人做。比如狗需要吃饭,就通过delegate通知主人,主人就会给他做饭、盛饭、倒水,这些操作,这些狗都不需要关心,只需要调用delegate(代理人)就可以了,由其他类完成所需要的操作。所以delegate是一对一关系。
block是delegate的另一种形式,是函数式编程的一种形式。使用场景跟delegate一样,相比delegate更灵活,而且代理的实现更直观。
25.写一个单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
+ (AccountManager *)sharedManager
{
static AccountManager *sharedAccountManagerInstance = nil;
static dispatch_once_t predicate;
dispatch_once(&predicate, ^{
sharedAccountManagerInstance = [[self alloc] init];
});
return sharedAccountManagerInstance;
}
// Swift
class ShareManager {
static let shared = ShareManager()
}
26. iOS 使用单例要注意什么问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
在iOS开发中,单例(Singleton)是一种常用的设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。使用单例时需要注意以下几个问题:
线程安全:
在多线程环境中,需要确保单例的实例化过程是线程安全的。可以通过锁、dispatch_once或NSThread等机制来保证。
懒加载:
单例通常采用懒加载的方式,即在第一次使用时才创建实例。这可以延迟资源的消耗,但需要确保懒加载的线程安全。
内存管理:
单例对象的生命周期与应用程序的生命周期相同,因此需要注意内存泄漏问题,特别是在使用大量资源或与其他对象有强引用关系时。
全局访问:
单例提供了全局访问点,但过度使用全局状态可能导致代码难以测试和维护。应谨慎使用单例,避免滥用。
配置和状态管理:
如果单例用于存储配置信息或状态,需要考虑线程安全和状态一致性问题。
子类化:
单例对象通常不应该被子类化。如果需要扩展单例的功能,可以考虑使用其他设计模式。
解耦:
单例作为全局访问点,可能导致代码之间的耦合度增加。使用依赖注入等技术可以降低耦合度。
测试性:
单例的全局性和唯一性可能会影响单元测试。可以通过依赖注入或使用协议来提高测试性。
资源竞争:
在多线程访问单例时,需要确保对共享资源的访问是同步的,避免出现竞态条件。
性能考虑:
单例的创建和初始化可能涉及重量级操作,需要考虑性能影响。确保单例的初始化过程尽可能高效。
依赖关系管理:
单例可能会引入隐式依赖,特别是在复杂的系统中。明确管理依赖关系,避免循环依赖。
单例模式的替代:
在某些情况下,可以考虑使用其他设计模式,如工厂模式、服务定位器等,作为单例的替代方案。
内存警告处理:
单例对象需要正确处理内存警告(如UIApplicationDidReceiveMemoryWarningNotification),在必要时释放占用的资源。
通过注意这些问题,可以有效地使用单例模式,同时避免潜在的陷阱和问题。单例模式在iOS开发中非常有用,但应谨慎使用,确保代码的健壳性、可维护性和测试性。
27.Swift中Self与self的区别
在Swift编程语言中,Self和self是两个不同的概念,它们在类、结构体或枚举的上下文中使用,但含义和用途不同:
self
self是Swift中的一个特殊的实例变量,它代表了当前类的实例。- 它用于访问当前实例的属性、方法和其他实例成员。
- 当你在一个实例的方法或属性访问器中访问同一个实例的另一个成员时,为了避免歧义,你需要使用
self。 self是可选的,如果上下文清晰,你可以省略它。
示例:
1
2
3
4
5
6
7
8
9
10
11
class Person {
var name: String
init(name: String) {
self.name = name // 使用self来避免与参数name冲突
}
func introduce() {
print("My name is \(name)") // 可以省略self
}
}
Self
Self是一个类型别名,代表了当前类、结构体或枚举的类型。- 它在类型上下文中使用,例如在返回类型、泛型约束或类型转换时。
Self提供了一种引用当前类型的方式,而不必使用具体的类型名称,这在泛型编程和协议扩展中非常有用。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
protocol Animal {
static func create() -> Self // Self代表实现了该协议的具体类型
}
struct Dog: Animal {
static func create() -> Self {
return Dog()
}
}
// 使用Self进行泛型约束
func printType<T>(_ item: T) where T: Animal {
print("Item is of type \(T.self)") // T.self是T类型的类型别名
}
self是实例的引用,用于区分局部变量和实例成员。
Self是类型的引用,用于泛型编程和协议实现中,代表当前的类型。
卓同学Swift 面试题
1.class 和 struct 的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class和struct的区别:
类型语义:
class是引用类型,所有对类的实例的引用都指向同一个数据。
struct是值类型,结构体实例的每次赋值或传递都会创建该实例的一个新copy。
继承:
class支持继承,可以有子类。
struct不支持继承。
可变性:
class的实例默认是可变的,可以在实例方法中改变其属性。
struct的实例默认是不可变的,如果需要改变属性,必须在方法中声明加上关键字 mutating。
内存管理:
class实例在堆上分配,由ARC (自动引用计数) 管理,开发者需要注意循环引用等问题。
struct实例在栈上分配,它的内存会自动释放,这有助于减少内存泄漏和简化内存管理。
性能:
class由于引用相同数据,在处理大型数据结构时提供更好的性能。
struct的复制可能涉及更多的内存操作,但在多线程环境中提供了天然线程安全性。
2.不通过继承,代码复用(共用)的方式有哪些
1
2
3
4
5
6
7
8
9
10
11
12
13
代码复用的好处:
可以降低开发成本、增加代码的可靠性并提高它们的一致性。
在Swift中,除了通过继承,还可以通过Extension扩展、Protocol协议来实现代码复用。
Extension
就是为一个已有的类、结构体、枚举类型或者协议类型添加新功能,比如:
1.添加计算型属性和计算型类型属性
2.定义实例方法和类型方法
3.提供新的构造器
4.使一个已有类型符合某个协议
Protocol
规定了用来实现某一特定任务或者功能的方法、属性,以及其他需要的东西。
类、结构体或枚举都可以遵循协议,并为协议定义的这些要求提供具体实现。
3.Set 独有的方法有哪些?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 根据两个集合中都包含的值创建的一个新的集合
intersect(_:)
// 根据只在一个集合中但不在两个集合中的值创建一个新的集合
exclusiveOr(_:)
// 根据两个集合的值创建一个新的集合
union(_:)
// 根据不在该集合中的值创建一个新的集合
subtract(_:)
//判断一个集合中的值是否也被包含在另外一个集合中
isSubsetOf(_:)
//判断一个集合中包含的值是否含有另一个集合中所有的值
isSupersetOf(_:)
isStrictSubsetOf(:)
// 判断一个集合是否是另外一个集合的子集合或者父集合并且和特定集合不相等
isStrictSupersetOf(:)
//判断两个集合是否不含有相同的值
isDisjointWith(_:)
4.实现一个 min 函数,返回两个元素较小的元素
1
2
3
4
// 一定要遵守 Comparable 协议,因为并不是所有的类型都具有“可比性”
func min<T: Comparable>(_ a: T, _ b: T) -> T {
return a < b ? a : b
}
5.map、filter、reduce 的作用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// map 是Array类的一个方法,可以使用它来对数组的每个元素进行转换,组成新的数组
let intArray = [1, 3, 5]
let stringArr = intArray.map {
return "\($0)" // ["1", "3", "5"]
}
// filter 用于选择数组元素中满足某种条件的元素,组成新的数组
let filterArr = intArray.filter {
return $0 > 1 // [3, 5]
}
// reduce 把数组元素组合计算为一个值
let result = intArray.reduce(0) {
return $0 + $1 // 9
}
6.Swift中map 与 flatmap 、compactmap的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
map
1.map 函数对集合中的每个元素应用一个转换函数,并返回一个新的集合,其中包含转换后的元素。
2.它不会改变原始集合的结构,只是将每个元素转换为新的形式。
flatMap
1.flatMap 函数也对集合中的每个元素应用一个转换函数,转换函数返回一个序列,然后将这些序列“展平”到一个单一的集合中。
2.flatMap 常用于处理可选值,将嵌套的可选展平。
compactMap
1.compactMap 函数类似于 flatMap,但它专门用于处理可选类型的集合。
2.它将每个可选元素应用转换函数,如果结果是 nil,则该元素会被忽略;如果结果是非 nil 的值,则将其包含在返回的数组中。
3.compactMap 可以看作是 map 和 flatMap 的结合,它既转换元素,也展平结果。
区别总结:
1.map 仅用于转换元素,不处理可选类型,也不会展平结果。
2.flatMap 用于转换元素并展平结果,适用于处理嵌套的序列或可选值。
3.compactMap 用于处理可选类型的集合,转换并展平结果,同时忽略 nil 值。
7.什么是 Copy on Write
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
1.Copy-on-Write 基本概念
是一种优化策略,减少不必要的内存复制。
允许多个引用共享同一个数据对象,直到其中一个引用需要修改数据时,才会真正进行复制操作。
可以避免在数据未被修改时进行不必要的复制,从而节省内存和提高性能。
为了提升性能,Struct, String、Array、Dictionary、Set采取了Copy On Write的技术
2.线程安全
在多线程环境中,Copy on Write可以作为一种线程安全策略。当多个线程访问同一数据时,只有当一个线程需要修改数据时,才会创建数据的副本,其他线程仍然可以访问原始数据。
iOS中的实现
在iOS中,Copy-on-Write主要通过NSMutableCopying协议来实现。这个协议要求实现mutableCopyWithZone:方法,该方法用于创建对象的可变副本。当对象被修改时,系统会自动调用这个方法来创建副本。
@interface MyClass : NSObject <NSMutableCopying>
@end
@implementation MyClass
- (id)mutableCopyWithZone:(NSZone *)zone {
// 创建对象的副本
MyClass *newObject = [[MyClass allocWithZone:zone] init];
// 复制数据到新对象
// ...
return newObject;
}
@end
// Swift
let originalArray = [1, 2, 3]
var mutableArray = originalArray // 此时没有复制
mutableArray.append(4) // 写操作,此时会复制originalArray并修改副本
print(originalArray) // 输出 [1, 2, 3],原始数组未被修改
print(mutableArray) // 输出 [1, 2, 3, 4],修改发生在副本上
注意事项
使用Copy on Write时,需要考虑写操作的频率。如果写操作非常频繁,可能会导致性能下降,因为每次写操作都需要复制数据。
在多线程环境中,Copy on Write可能导致额外的同步开销,需要仔细设计以确保线程安全。
8.如何获取当前代码的函数名和行号
1
2
3
4
获取文件名: #file
获取函数名: #function
获取行号:#line
获取列:#column
9.如何声明一个只能被类 conform 的 protocol
1
2
3
4
// 协议的继承列表中,通过添加 class 关键字来限制协议只能被class类型遵循,而结构体或枚举不能遵循该协议。class 关键字必须第一个出现在协议的继承列表中,在其他继承的协议之前:
protocol SomeClassOnlyProtocol: class, SomeInheritedProtocol {
// 这里是类类型专属协议的定义部分
}
10.guard 使用场景
1
2
3
4
5
6
7
使用 guard 来表达 “提前退出”的意图:
1.在验证入口条件时
2.在成功路径上提前退出
3.在可选值解包等
尽量避免使用的场景:
1.不要用 guard 替代琐碎的 if..else 语句
2.不要在 guard 的 else 语句中放入复杂代码
11.defer 使用场景
1
2
3
4
5
6
7
8
9
10
11
12
13
defer 语句用于在退出当前作用域之前执行代码.
例如:
手动管理资源时,比如 关闭文件描述符,或者即使抛出了错误也需要执行一些操作时,就可以使用 defer 语句。
如果多个 defer 语句出现在同一作用域内,那么它们执行的顺序与出现的顺序相反
func testDefer() {
defer { print("First") }
defer { print("Second") }
defer { print("Third") }
}
testDefer()
// 打印 “Third”
// 打印 “Second”
// 打印 “First”
12.String 与 NSString 的关系与区别
1
2
Swift 的String类型与 Foundation NSString 类进行了无缝桥接。
最大的区别就是:String是值类型,而NSString是引用类型。 其他方面的差异就体现在各自api 上的差异。
13.怎么获取一个 String 的长度
1
2
3
let length1 = "string".characters.count
let length2 = "string".data(using: .utf8).count
let length3 = ("string" as NSString).length
14.如何截取 String 的某段字符串
1
每一个String值都有一个关联的索引(index)类型,String.Index,它对应着字符串中的每一个Character的位置
15.throws 和 rethrows 的用法与作用
- throw异常: 表示这个函数可能会抛出异常,无论作为参数的闭包是否抛出异常
- rethrow异常: 表示这个函数本身不会抛出异常,但如果作为参数的闭包抛出了异常,那么它会把异常继续抛上去
1
public func map<T>(_ transform: (Element) throws -> T) rethrows -> [T]
16.try? 和 try!是什么意思
1
2
try?: 是用来修饰一个可能会抛出错误的函数。它会将错误转换为可选值,当调用try? 函数或方法语句时候,如果函数或方法抛出错误,程序不会发崩溃,而返回一个nil;如果没有抛出错误则返回可选值
try!: 会忽略错误传递链,并声明“do or die”。如果被调用函数或方法没有抛出异常,那么一切安好;但是如果抛出异常,立即崩溃。
17.associatedtype 的作用
在Swift中,associatedtype 是一个在协议中使用的关键字,用于定义一个与协议关联的类型来实现泛型功能的。associatedtype 主要用于以下场景:
- 类型安全的协议:当协议需要定义一个或多个类型,但这些类型在协议定义时尚未确定时,可以使用 associatedtype 来定义一个类型占位符。
- 泛型协议:associatedtype 允许协议本身具有泛型行为,使得协议的实现可以根据具体的类型参数来定制。
- 协议的灵活性:使用 associatedtype 可以使得协议的实现更加灵活,因为具体的类型可以在协议被某个类型实现时才确定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
protocol Container {
associatedtype Item
mutating func append(item: Item)
var count: Int { get }
}
struct IntArray: Container {
typealias Item = Int
var items: [Item] = []
mutating func append(item: Item) {
items.append(item)
}
var count: Int {
return items.count
}
}
// associatedtype 必须在协议的扩展中或者协议的实现中被具体化。
// 一个协议可以定义多个 associatedtype。
// associatedtype 可以被用来声明属性、方法的参数和返回类型。
18.什么时候使用 final
final关键字用于限制类、类成员(如方法、构造器、属性)以及协议的继承和重写。以下是使用final关键字的一些场景:
- 限制类的继承:
- 当你声明一个类为
final时,这个类不能被其他类继承。这可以用来防止类的扩展,确保类的实现不会被改变。
- 当你声明一个类为
- 限制类成员的重写:
- 你可以将类的方法、构造器或属性声明为
final,这样它们就不能被子类重写。这有助于保护成员的实现不被改变。
- 你可以将类的方法、构造器或属性声明为
- 优化性能:
- 由于
final类或成员不能被重写,编译器可以进行更多的优化。这可以提高运行时的性能。
- 由于
- 使用协议:
- 从Swift 5开始,你可以将协议的属性声明为
final,这意味着协议的实现不能是存储属性,而必须是计算属性。
- 从Swift 5开始,你可以将协议的属性声明为
- 明确设计意图:
- 使用
final可以清晰地表达你的设计意图,即某些类或成员不应该被扩展或修改。
- 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 一个final类,不能被继承
final class ImmutableClass {
let value: Int
init(value: Int) {
self.value = value
}
}
// 一个final方法,不能被重写
class BaseClass {
final func performAction() {
print("Performing action in BaseClass")
}
}
// 一个final构造器,不能被重写
class MyClass {
final init() {
print("MyClass initialized")
}
}
// 一个final协议属性,必须实现为计算属性
protocol MyProtocol {
final var value: Int { get }
}
使用final的考虑因素
- 封装性:如果你希望确保类的实现细节不被外部访问或修改,使用
final可以提供更好的封装性。 - 性能:在某些情况下,使用
final可以提高性能,因为编译器可以做出更多的优化。 - 设计灵活性:使用
final可能会减少代码的灵活性,因为它限制了继承和重写。在设计API时需要权衡这一点。
19.public 和 open 的区别
open
- open 修饰的 class 在 Module 内部和外部都可以被访问和继承
- open 修饰的 func 在 Module 内部和外部都可以被访问和重载(override)
**public **
- public 修饰的 class 在 Module 内部可以访问和继承,在外部只能访问
- public 修饰的 func 在 Module 内部可以被访问和重载(override),在外部只能访问
20.声明一个只有一个参数没有返回值闭包的别名
1
typealias IntBlock = (Int) -> Void
21.Self 的使用场景
1
2
3
4
5
6
7
// 协议声明
protocol Hello {
func sayHello() -> Self
}
// 协议扩展
protocol MyProtocol { }
extension MyProtocol where Self: UIView { }
22.dynamic 的作用
dynamic关键字用于告诉编译器某些属性、方法或下标访问器应该在运行时解析,而不是在编译时。这通常与继承和多态性相关。
- dynamic 可以用来修饰变量或函数/方法,告诉编译器使用动态分发而不是静态分发。
- 使用动态分发,可以更好的与OC中runtime的一些特性(如CoreData,KVC/KVO)进行交互
- 标记为dynamic的变量/函数会隐式的加上@objc关键字,它会使用OC的runtime机制
23.什么时候使用 @objc
在Swift中,@objc是一个属性修饰符,用于指示编译器将相应的成员(如方法、属性、类、协议等)暴露给Objective-C运行时。以下是使用@objc的一些主要场景:
- 与Objective-C代码互操作:
- 当你需要在Swift中定义可以被Objective-C代码调用的成员时,使用
@objc。
- 当你需要在Swift中定义可以被Objective-C代码调用的成员时,使用
- 实现Objective-C协议:
- 如果Swift类需要实现一个Objective-C定义的协议,那么实现的成员需要使用
@objc。
- 如果Swift类需要实现一个Objective-C定义的协议,那么实现的成员需要使用
- 使用Objective-C运行时特性:
- 如果你使用Objective-C的运行时特性,如动态方法解析(使用
dynamic关键字)或消息转发,成员需要用@objc标记。
- 如果你使用Objective-C的运行时特性,如动态方法解析(使用
- 使用Objective-C API:
- 当Swift代码需要使用Objective-C API,特别是那些需要使用选择器(selectors)或通过运行时消息传递调用的方法时。
- 定义Objective-C风格的类:
- 如果你需要定义一个类,它将作为Objective-C类使用,或者需要被子类化,那么这个类应该使用
@objc。
- 如果你需要定义一个类,它将作为Objective-C类使用,或者需要被子类化,那么这个类应该使用
- 使用KVO(Key-Value Observing):
- 当你在Swift中实现属性的键值观察时,被观察的属性需要用
@objc标记。
- 当你在Swift中实现属性的键值观察时,被观察的属性需要用
- 使用Objective-C集合类:
- 当你希望Swift定义的类可以作为Objective-C集合类(如
NSArray、NSDictionary)的元素时。
- 当你希望Swift定义的类可以作为Objective-C集合类(如
注意事项
- 使用
@objc成员的类必须继承自NSObject或其子类。 @objc成员可以被子类重写,即使在Swift中使用final关键字,Objective-C代码仍然可以调用父类的实现。- 使用
@objc会增加一些运行时开销,因为它涉及到Objective-C运行时。
24.Optional(可选型)是用什么实现的
Optional 是一种枚举类型,用来表示一个值可能是某种类型或者没有值。Optional 的实现基于以下两种情况:
None: 表示没有值,即Optional是空的。Some(Wrapped): 表示有一个值,Wrapped是实际存储的值的类型。
Swift中的Optional枚举定义如下:
1
2
3
4
5
// 这里的`Wrapped`是泛型参数,表示`Optional`可以包含任何类型的值。
enum Optional<Wrapped> {
case none
case some(Wrapped)
}
Optional的使用场景:
- 当函数可能没有返回值时,可以使用
Optional来返回nil。 - 当一个变量可能没有被赋值时,可以使用
Optional来表示这个变量。 Optional在解包(unwrapping)时需要进行安全检查,以避免运行时错误。
Optional的常见操作:
- 解包(Unwrapping): 使用
if let或guard let来安全地解包Optional,获取其内部的值。 - 可选链(Optional Chaining): 使用
?来安全地访问嵌套的可选属性或调用可选对象的方法。 - 空合并运算符(Nil Coalescing Operator): 使用
??来提供一个默认值,当Optional为空时使用。
25.如何自定义下标获取
1
2
3
4
5
6
7
8
9
// 使用subscript语法
struct TimesTable {
let multiplier: Int
subscript(index: Int) -> Int {
return multiplier * index
}
}
let threeTimesTable = TimesTable(multiplier: 3)
threeTimesTable[6] //18
26. ?? 的作用
1
2
3
?? 是空合运算符。
比如a ?? b ,将对可选类型a进行为空判断,如果a包含一个值,就进行解封,否则就返回一个默认值b。
表达式 a 必须是 Optional 类型。默认值 b 的类型必须要和 a 存储值的类型保持一致
27. lazy 的作用
使用lazy关键字修饰struct 或class 的成员变量,达到懒加载的效果。一般有以下使用场景:
- 属性开始时,还不确定是什么活着还不确定是否被用到
- 属性需要复杂的计算,消耗大量的CPU
- 属性只需要初始化一次
28.一个类型表示选项,可以同时表示有几个选项选中(类似 UIViewAnimationOptions ),用什么类型表示
使用选项集合:OptionSet。示例:
1
2
3
4
5
6
7
8
struct AnimationOptions: OptionSet {
let rawValue: Int
// 使用2的幂次方来定义选项
static let curveEaseInOut = AnimationOptions(rawValue: 1 << 0)
static let curveEaseIn = AnimationOptions(rawValue: 1 << 1)
static let curveEaseOut = AnimationOptions(rawValue: 1 << 2)
static let allowUserInteraction = AnimationOptions(rawValue: 1 << 3)
}
29. inout 的作用
inout参数是一种特殊的函数或方法参数,它允许向函数或方法传递一个值,并且允许函数或方法修改这个值,同时这个修改也会影响到原始的变量。
1
2
3
4
5
6
func increment(value: inout Int) {
value += 1
}
var number = 10
increment(value: &number) // 使用 & 来获取number的引用
print(number) // 输出 11,number的值被increment函数修改了
注意事项:
- 只有变量可以作为
inout参数传递,常量和字面量值不能作为inout参数。 inout参数必须在调用时明确标记为&,以表明它们是引用传递。- 在函数或方法内部,你不能对
inout参数使用let来重新声明为常量。 - 使用
inout参数时需要小心,因为它们可能会意外地修改传入的变量。
30.Error 如果要兼容 NSError 需要做什么操作
想让我们的自定义Error可以转成NSError,实现CustomNSError就可以完整的as成NSError.
1
2
3
4
5
6
7
8
9
10
11
12
13
/// Describes an error type that specifically provides a domain, code,
/// and user-info dictionary.
public protocol CustomNSError : Error {
/// The domain of the error.
public static var errorDomain: String { get }
/// The error code within the given domain.
public var errorCode: Int { get }
/// The user-info dictionary.
public var errorUserInfo: [String : Any] { get }
}
31.下面的代码都用了哪些语法糖 [1, 2, 3].map{ $0 * 2 }
1
2
3
4
1.尾随闭包(Trailing Closures), 如果函数的最后一个参数是闭包,则可以省略 ()
2.如果该闭包只有一行,则可以省略 return
3.类型推断,返回值被推断为Int
4.$0 代表集合的元素
32.什么是高阶函数
高阶函数(Higher-order function)是至少满足以下条件之一的函数:
- 接受一个或多个函数作为参数:高阶函数可以接收其他函数作为输入参数,这使得函数能够操作或修改函数的行为。
- 返回一个函数作为结果:高阶函数可以返回一个新的函数,这通常用于创建定制化的行为或延迟执行。
高阶函数是函数式编程范式的关键概念之一,它使得代码更加灵活和可重用。Swift标准库中包含了一些高阶函数的例子,如map、filter、reduce等。
1
2
3
4
5
6
7
8
9
10
11
// 示例1:接受函数作为参数
func transformArray<T, U>(array: [T], transform: (T) -> U) -> [U] {
var transformedArray = [U]()
for item in array {
transformedArray.append(transform(item))
}
return transformedArray
}
let numbers = [1, 2, 3, 4, 5]
let squares = transformArray(array: numbers, transform: { $0 * $0 })
33.如何解决引用循环
解决引用循环问题,Swift提供了几种方法:
- 弱引用(Weak):
- 使用
weak修饰符来声明一个变量,表示这个变量不拥有它所引用的对象。当被引用的对象被释放时,weak变量会自动置为nil。但是,weak变量不能被初始化为nil之外的任何值,并且不能被重写。
- 使用
- 无主引用(Unowned):
- 使用
unowned修饰符来声明一个变量,表示这个变量总是拥有它所引用的对象,并且假设引用的对象在声明变量的生命周期内总是存在的。如果被引用的对象先于unowned变量释放,将会导致运行时崩溃。unowned变量可以被初始化,并且可以被重写。
- 使用
- 闭包中的循环引用:
- 如果循环引用发生在闭包中,可以使用
[weak self]或[unowned self]来捕获self。这告诉闭包不要捕获self的强引用。
- 如果循环引用发生在闭包中,可以使用
- 协议委托(Delegate):
- 如果循环引用发生在协议委托关系中,应该使用
weak或unowned来声明委托属性。
- 如果循环引用发生在协议委托关系中,应该使用
- 定时器和事件监听器:
- 如果循环引用发生在定时器或事件监听器中,确保在对象被销毁时移除监听器或定时器。
- 使用
NSTimer:- 如果你使用
NSTimer,确保使用块(block)而不是目标-动作(target-action)模式来避免循环引用,或者在定时器的块中使用弱引用。
- 如果你使用
34.下面的代码会不会崩溃,说出原因
1
2
3
4
var mutableArray = [1,2,3]
for _ in mutableArray {
mutableArray.removeLast()
}
在Swift的早期版本中,这种操作可能会直接导致程序崩溃。但是,从Swift 4.2开始,标准库的Array和其他集合类型使用了一种新的迭代器实现,这使得在遍历时修改集合更加安全。当你在遍历过程中修改集合时,会抛出一个CollectionMutateWhileIterating错误,而不是导致程序崩溃。
这个错误可以通过以下方式捕获:
1
2
3
4
5
6
7
8
var mutableArray = [1, 2, 3]
do {
try mutableArray.makeIterator().forEach { _ in
mutableArray.removeLast()
}
} catch {
print(error) // 打印错误信息
}
在这个例子中,我们使用makeIterator()来获取一个迭代器,并使用forEach来遍历集合。如果在遍历过程中修改了集合,会抛出一个错误,并且可以通过catch块来捕获和处理这个错误。但最佳实践仍然是避免在遍历过程中修改集合,以保证代码的可读性和安全性。
35.给集合中元素是字符串的类型增加一个扩展方法,应该怎么声明
1
2
3
4
5
6
7
8
extension Sequence where Iterator.Element == Int {
// your code
}
protocol SomeProtocol {}
extension Collection where Iterator.Element: SomeProtocol {
// your code
}
36.定义静态方法时关键字 static 和 class 有什么区别
static和class都是用来指定类方法class关键字指定的类方法可以被overridestatic关键字指定的类方法不能被override