搜索算法是利用计算机的高性能来有目的的穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。现阶段一般有枚举算法、深度优先搜索、广度优先搜索、A算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。
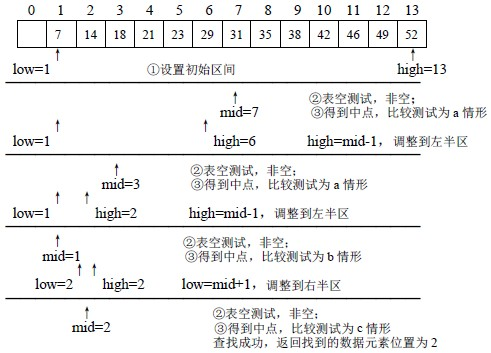
二分搜索
基本思路
- 在有序表中,取中间元素作为比较对象,若给定值与中间元素的要查找的数相等,则查找成功;若给定值小于中间元素的要查找的数,则在中间元素的左半区继续查找;
- 若给定值大于中间元素的要查找的数,则在中间元素的右半区继续查找。不断重复上述查找过 程,直到查找成功,或所查找的区域无数据元素,查找失败
实现步骤
- 在有序表中,取中间元素作为比较对象,若给定值与中间元素的要查找的数相等,则查找成功;
- 若给定值小于中间元素的要查找的数,则在中间元素的左半区继续查找;
- 若给定值大于中间元素的要查找的数,则在中间元素的右半区继续查找。
- 不断重复上述查找过 程,直到查找成功,或所查找的区域无数据元素,查找失败。
C语言代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
int findKey(int values[], int length, int key) {
// 定义一个变量记录最小索引
int min = 0;
// 定义一个变量记录最大索引
int max = length - 1;
// 定义一个变量记录中间索引
int mid = (min + max) * 0.5;
while (min <= max) {
// 如果mid对应的值 大于 key, 那么max要变小
if (values[mid] > key) {
max = mid - 1;
// 如果mid对应的值 小于 key, 那么min要变
}else if (values[mid] < key) {
min = mid + 1;
}else {
return mid;
}
// 修改完min/max之后, 重新计算mid的值
mid = (min + max) * 0.5;
}
return -1;
}
Swift语言实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/*
1. mid被定义在while循环外面,如果被定义在里面,则每次循环都要重新给mid分配内存空间,从而会造成不必要的浪费;
定义再循环之外,则每次循环只是重新赋值。
2. 每次重新给mid赋值不能写成mid = (right + left) / 2。这种写法表面上看没有问题,但当数组非常长、算法又已经搜索到了最右边部分时,right + left就会非常大,造成溢出,导致程序崩溃,所以,解决问题的办法是写成mid = (right - left) / 2 + left
*/
func binarySearchs(_ values: [Int], _ target: Int) -> Bool {
var left = 0, mid = 0, right = values.count - 1
while left <= right {
mid = (right - left) / 2 + left
if values[mid] == target {
return true
} else if values[mid] < target {
left = mid + 1
} else {
right = mid - 1
}
}
return false
}
递归实现二分搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
func binarySearch(_ values: [Int], _ target: Int) -> Bool {
return binarySearch(values, target, left: 0, right: values.count - 1)
}
func binarySearch(_ values: [Int], _ target: Int, left: Int, right: Int) -> Bool {
guard left <= right else {
return false
}
let mid = (right - left) / 2 + left
if values[mid] == target {
return true
} else if values[mid] < target {
return binarySearch(values, target, left: mid + 1, right: right)
} else {
return binarySearch(values, target, left: left, right: mid - 1)
}
}
练习
第一题: 版本崩溃
上面的二分搜索基本上稍微有点基本功的都能写出来。所以,真正面试的时候,最多也就是问问概念,不会真正让你实现的。真正的面试题,长下面这个样子:
有一个产品发布了n个版本。它遵循以下规律:假如某个版本崩溃了,后面的所有版本都会崩溃。 举个例子:一个产品假如有5个版本,1,2,3版都是好的,但是第4版崩溃了,那么第5个版本(最新版本)一定也崩溃。第4版则被称为第一个崩溃的版本。 现在已知一个产品有n个版本,而且有一个检测算法
func isBadVersion(version: Int) -> Bool可以判断一个版本是否崩溃。假设这个产品的最新版本崩溃了,求第一个崩溃的版本。
分析这种题目,同样还是先抽象化。我们可以认为所有版本为一个数组[1, 2, 3, …, n],现在我们就是要在这个数组中检测出满足 isBadVersion(version) == true中version的最小值。 很容易就想到二分搜索,假如中间的版本是好的,第一个崩溃的版本就在右边,否则就在左边。我们来看一下如何实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func findFirstBadVersion(_ version: Int) -> Int {
// 处理特殊情况
guard version >= 1 else {
return -1
}
var left = 1, right = version, mid = 0
while left < right {
mid = (right - left) / 2 + left
if isBadVersion(mid) {
right = mid
} else {
left = mid + 1
}
}
return right
}
func isBadVersion(_ version: Int) -> Bool {
return version == 8 ? true : false
}
这个实现方法要注意两点:
- 当发现中间版本(mid)是崩溃版本的时候,只能说明第一个崩溃的版本小于等于中间版本。所以只能写成 right = mid
- 当检测到剩下一个版本的时候,我们已经无需在检测直接返回即可,因为它肯定是崩溃的版本。所以while循环不用写成left <= right
第二题:搜索旋转有序数组
上面的题目是一个简单的二分搜索变种。我们来看一个复杂版本的:
一个有序数组可能在某个位置被旋转。给定一个目标值,查找并返回这个元素在数组中的位置,如果不存在,返回-1。假设数组中没有重复值。 举个例子:[0, 1, 2, 4, 5, 6, 7]在4这个数字位置上被旋转后变为[4, 5, 6, 7, 0, 1, 2]。搜索4返回0。搜索8则返回-1。
假如这个有序数组没有被旋转,那很简单,我们直接采用二分搜索就可以解决。现在被旋转了,还可以采用二分搜索吗? 我们先来想一下旋转之后的情况。第一种情况是旋转点选的特别前,这样旋转之后左半部分就是有序的;第二种情况是旋转点选的特别后,这样旋转之后右半部分就是有序的。如下图:
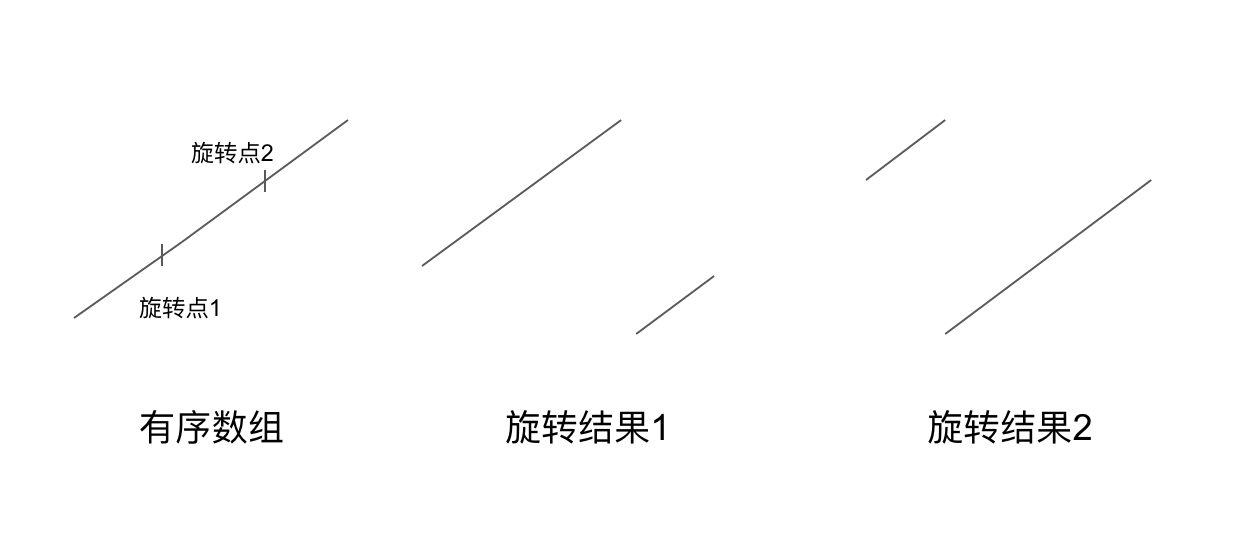
那么怎么判断是结果1还是结果2呢?我们可以选取整个数组中间元素(mid) ,与数组的第1个元素(left)进行比较 – 如果 mid > left,则是旋转结果1,那么数组的左半部分就是有序数组,我们可以在左半部分进行正常的二分搜索;反之则是结果二,数组的右半部分为有序数组,我们可以在右半部分进行二分搜索。
这里要注意一点,即使我们一开始清楚了旋转结果,也要判断一下目标值所落的区间。对于旋转结果1,数组左边最大的值是mid,最小值是left。假如要找的值target落在这个区间内,则使用二分搜索。否则就要在右边的范围内搜索,这个时候相当于回到了一开始的状态,有一个旋转的有序数组,只不过我们已经剔除了一半的搜索范围。对于旋转结果2,也类似处理。全部代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/*
一个有序数组可能在某个位置被旋转。给定一个目标值,查找并返回这个元素在数组中的位置,如果不存在,返回-1。假设数组中没有重复值。
举个例子:[0, 1, 2, 4, 5, 6, 7]在4这个数字位置上被旋转后变为[4, 5, 6, 7, 0, 1, 2]。搜索4返回0。搜索8则返回-1。
*/
func search(nums: [Int], target: Int) -> Int {
var (left, mid, right) = (0, 0, nums.count - 1)
while left <= right {
mid = (right - left) / 2 + left
if nums[mid] == target {
return 1
}
if nums[mid] >= nums[left] {
if nums[mid] > target && target >= nums[left] {
right = mid - 1
} else {
left = mid + 1
}
} else {
if nums[mid] < target && target <= nums[right] {
left = mid + 1
} else {
right = mid - 1
}
}
}
return -1
}
大家可以想一下假如旋转后的数组中有重复值比如[3,4,5,3,3,3]该怎么处理?
iOS中搜索与排序的配合使用
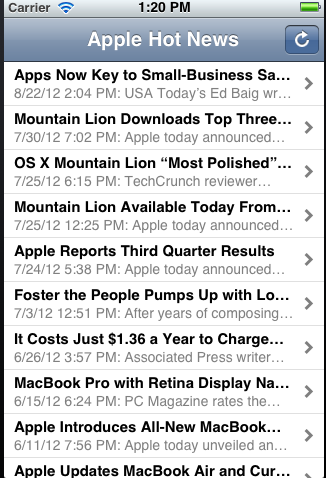
上图是iOS中开发的一个经典案例:新闻聚合阅读器(RSS Reader)。因为新闻内容经常会更新,所以每次下拉刷新这个UITableView或是点击右上角刷新按钮,经常会有新的内容加入到原来的dataSource中。刷新后合理插入新闻,就要运用到搜索和排列。
首先,写一个ArrayExtensions.swift;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/*
新闻聚合阅读器(RSS Reader)。因为新闻内容经常会更新,所以每次下拉刷新这个UITableView或是点击右上角刷新按钮,
经常会有新的内容加入到原来的dataSource中。刷新后合理插入新闻,就要运用到搜索和排列。
let insertIdx = news.indexForInsertingObject(object: singleNews) { (a, b) -> Int in
let newsA = a as! News
let newsB = b as! News
return newsA.compareDate(newsB)
}
news.insert(singleNews, at: insertIdx)
*/
extension Array {
func indexForInsertingObject(object: AnyObject, compare: ((_ a: AnyObject, _ b: AnyObject) -> Int)) -> Int {
var left = 0, right = self.count, mid = 0
while left < right {
mid = (right - left) / 2 + left
if compare(self[mid] as AnyObject, object) < 0 {
left = mid + 1
} else {
right = mid
}
}
return left
}
}
然后在FeedsViewController(就是显示所有新闻的tableView的controller)里面使用这个方法。一般情况下,FeedsViewController里面会有一个dataSource,比如一个装新闻的array。这个时候,我们调用这个方法,并且让它每次都按照新闻的时间进行排序:
1
2
3
4
5
6
7
let insertIdx = news.indexForInsertingObject(object: singleNews) { (a, b) -> Int in
let newsA = a as! News
let newsB = b as! News
return newsA.compareDate(newsB)
}
news.insert(singleNews, at: insertIdx)
二分搜索是一种十分巧妙的搜索方法,它的复杂度是主流算法中最低的。正以为其十分高效,它会经常配合排序出现在各种日常coding和iOS开发中。当然,二分搜索也会出现各种各样的变种,其实万变不离其宗,关键是想方法每次减小一半的搜索范围即可。
深度和广度优先搜索
本节主要讲解两个更复杂的搜索算法 – 深度优先搜索(Depth-First-Search,以下简称DFS)和广度优先搜索(Breadth-First-Search,以下简称BFS)。
基本概念
DFS和BFS的具体定义这里不做赘述。笔者谈谈自己对此的形象理解:假如你在家中发现钥匙不见了,为了找到钥匙,你有两种选择:
- 从当前角落开始,顺着一个方向不停的找。假如这个方向全部搜索完毕依然没有找到钥匙,就回到起始角落,从另一个方向寻找,直到找到钥匙或所有方向都搜索完毕为止。这种方法就是DFS。
- 从当前角落开始,每次把最近所有方向的角落全部搜索一遍,直到找到钥匙或所有方向都搜索完毕为止。这种方法就是BFS。
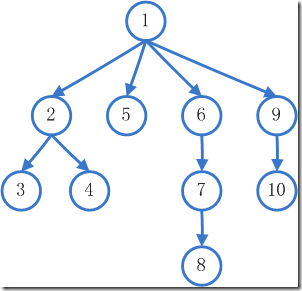
DFS的搜索步骤
- 1
- 2 -> 3 -> 4
- 5
- 6 ->7 -> 8
- 9 -> 10
即每次把一个方向彻底搜索完全后,才返回搜索下一个方向。 BFS的搜索步骤
- 1
- 2 -> 5 -> 6 -> 9
- 3 -> 4
- 7
- 10
- 8
即每次访问上一步周围所有方向上的角落。 在二叉树的时候,讲到了前序遍历和层级遍历,而这两者本质上就是DFS和BFS。
DFS的Swift实现
1
2
3
4
5
6
7
8
9
10
// 深度优先搜索(相当前序遍历)
func dfs(_ root: TreeNode?) {
guard let root = root else {
print("", terminator: "")
return
}
print("\(root.val) ", terminator: "")
dfs(root.left)
dfs(root.right)
}
BFS的Swift实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 广度优先搜索(相当层次遍历)
func bfs(_ root: TreeNode?) {
var result = [[TreeNode]]()
var level = [TreeNode]()
if let root = root {
level.append(root)
}
while !level.isEmpty {
result.append(level)
var nextLevel = [TreeNode]()
for node in level {
if let leftNode = node.left {
nextLevel.append(leftNode)
}
if let rightNode = node.right {
nextLevel.append(rightNode)
}
}
level = nextLevel
}
let res = result.map { $0.map { $0.val }}
print("\(res) ", terminator: "")
}
DFS的实现用递归,BFS的实现用循环(配合队列)。
练习
实现一个找单词App: 给定一个初始的字母矩阵,你可以从任一字母开始,上下左右,任意方向、任意长度,选出其中所有单词。
很多人拿到这道题目就懵了。。。完全不是我们熟悉的UITableView或者UICollectionView啊,这要咋整。我们来一步步分析。
第一步: 实现字母矩阵
首先,我们肯定有个字符二阶矩阵作为输入,姑且记做:matrix: [[Character]]。现在要把它展现在手机上,那么可行的方法,就是创建一个UILabel二维矩阵,记做labels: [[UILabel]],矩阵中每一个UILabel对应的内容就是相应的字母。同时,我们可以维护2个全局变量,xOffset和yOffset。然后在for循环中创建相应的UILabel同时将其添加进lables中便于以后使用,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var xOffset = 0
var yOffset = 0
let cellWidth = UIScreen.mainScreen().bounds.size.width / matrix[0].count
let cellHeight = UIScreen.mainScreen().bounds.size.height / matrix.count
for i in 0 ..< matrix.count {
for j in 0 ..< matrix[0].count {
let label = UILabel(frame: CGRect(x: xOffset, y: yOffset, width: cellWidth, height: cellHeight))
label.text = String(matrix[i][j])
view.addSubView(label)
labels.append(label)
xOffset += cellWidth
}
xOffset = 0
yOffset += cellHeight
}
第二步: 用DFS实现搜索单词
现在要实现搜索单词的核心算法了。我们先简化要求,假如只在字母矩阵中搜索单词”crowd”该怎么做? 首先我们要找到 “c” 这个字母所在的位置,然后再上下左右找第二个字母 “r” ,接着再找字母 “o” 。。。以此类推,直到找到最后一个字母 “d” 。如果没有找到相应的字母,我们就回头去首字母 “c” 所在的另一个位置,重新搜索。 这里要注意一个细节,就是我们不能回头搜索字母。比如我们已经从 “c” 开始向上走搜索到了 “r” ,这个时候就不能从 “r” 向下回头 – 因为 “c” 已经访问过了。所以这里需要一个var visited: [[Bool]] 来记录访问记录。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
func searchWord(_ board: [[Character]]) -> Bool {
guard board.count > 0 && board[0].count > 0 else {
return false
}
let (m, n) = (board.count, board[0].count)
var visited = Array(repeating: Array(repeating: false, count: n), count: m)
var wordContent = [Character]("crowd".characters)
for i in 0 ..< m {
for j in 0 ..< n {
if dfs(board, wordContent, m, n, i, j, &visited, 0) {
return true
}
}
}
return false
}
func dfs(_ board: [[Character]], _ wordContent: [Character], _ m: Int, _ n: Int, _ i: Int, _ j: Int, _ visited: inout [[Bool]], _ index: Int) -> Bool {
if index == wordContent.count {
return true
}
guard i >= 0 && i < m && j >= 0 && j < n else {
return false
}
guard !visited[i][j] && board[i][j] == wordContent[index] else {
return false
}
visited[i][j] = true
if dfs(board, wordContent, m, n, i + 1, j, &visited, index + 1) || dfs(board, wordContent, m, n, i - 1, j, &visited, index + 1) || dfs(board, wordContent, m, n, i, j + 1, &visited, index + 1) || dfs(board, wordContent, m, n, i, j - 1, &visited, index + 1) {
return true
}
visited[i][j] = false
return false
}
第三步: 优化算法,进阶
好了现在我们已经知道了怎么搜索一个单词了,那么多个单词怎么搜索?首先题目是要求找出所有的单词,那么肯定事先有个字典,根据这个字典,我们可以知道所选字母是不是可以构成一个单词。所以题目就变成了:
已知一个字母构成的二维矩阵,并给定一个字典。选出二维矩阵中所有横向或者纵向的单词。
也就是实现以下函数:
1
func findWords(_ board: [[Character]], _ dict: Set<String>) -> [String] {}
我们刚才已经知道如何在矩阵中搜索一个单词了。所以最暴力的做法,就是在矩阵中,搜索所有字典中的单词,如果存在就添加在输出中。 这个做法显然复杂度极高:首先,每次DFS的复杂度就是O(n2),字母矩阵越大,搜索时间就越长;其次,字典可能会非常大,如果每个单词都搜索一遍,开销太大。这种做法的总复杂度为O(m·n2),其中m为字典中单词的数量,n为矩阵的边长。 这个时候就要引入Trie树(前缀树)。首先我们把字典转化为前缀树,这样的好处在于它可以检测矩阵中字母构成的前缀是不是一个单词的前缀,如果不是就没必要继续DFS下去了。这样我们就把搜索字典中的每一个单词,转化为了只搜字母矩阵。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
func findWords(_ board: [[Character]], _ dict: Set<String>) -> [String] {
var res = [String]()
let (m, n) = (board.count, board[0].count)
let trie = _convertSetToTrie(dict)
var visited = Array(repeating: Array(repeating: false, count: n), count: m)
for i in 0 ..< m {
for j in 0 ..< n {
_dfs(board, m, n, i, j, &visited, &res, trie, "")
}
}
return res
}
private func _dfs(_ board: [[Character]], _ m: Int, _ n: Int, _ i: Int, _ j: Int, inout _ visited: [[Bool]], inout _ res: [String], _ trie: Trie, _ str: String) {
// 越界
guard i >= 0 && i < m && j >= 0 && j < n else {
return
}
// 已经访问过了
guard !visited[i][j] else {
return
}
// 搜索目前字母组合是否是单词前缀
var str = str + "\(board[i][j])"
guard trie.prefixWith(str) else {
return
}
// 确认当前字母组合是否为单词
if trie.isWord(str) && !res.contains(str) {
res.append(str)
}
// 继续搜索上下左右四个方向
visited[i][j] = true
_dfs(board, m, n, i + 1, j, &visited, &res, trie, str)
_dfs(board, m, n, i - 1, j, &visited, &res, trie, str)
_dfs(board, m, n, i, j + 1, &visited, &res, trie, str)
_dfs(board, m, n, i, j - 1, &visited, &res, trie, str)
visited[i][j] = true
}
深度优先遍历和广度优先遍历是算法中略微高阶的部分,实际开发中,它也多与地图路径、棋盘游戏相关。虽然不是很常见,但是理解其基本原理并能熟练运用,相信可以使大家的开发功力更上一层楼。
进制转换(查表法)
实现思路:
- 将二进制、八进制、十进制、十六进制所有可能的字符都存入数组
- 利用按位与运算符和右移依次取出当前进制对应位置的值
- 利用取出的值到数组中查询当前位输出的结果
- 将查询的结果存入一个新的数组, 当所有位都查询存储完毕, 新数组中的值就是对应进制的值
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <stdio.h>
void toBinary(int num)
{
total(num, 1, 1);
}
void toOct(int num)
{
total(num, 7, 3);
}
void toHex(int num)
{
total(num, 15, 4);
}
void total(int num , int base, int offset)
{
// 1.定义表用于查询结果
char cs[] = {
'0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'a', 'b',
'c', 'd', 'e', 'f'
};
// 2.定义保存结果的数组
char rs[32];
// 计算最大的角标位置
int length = sizeof(rs)/sizeof(char);
int pos = length;//8
while (num != 0) {
int index = num & base;
rs[--pos] = cs[index];
num = num >> offset;
}
for (int i = pos; i < length; i++) {
printf("%c", rs[i]);
}
printf("\n");
}
int main()
{
toBinary(9);
return 0;
}